![[Generation Five]](/q/wp-content/themes/mach-go/images/GenerationFive.png)
![[Reliable And Maintainable Software For The Next Generation]](/q/wp-content/themes/mach-go/images/ReliableAndMaintainableSoftwareForTheNextGeneration.png)


Stop Catching Exceptions!
Motivation
It’s clear that a lot of programmers are uncomfortable with exceptions [1] [2]; in the feedback of an article I wrote about casting, it seemed that many programmers saw the throwing of a NullReferenceException at a cast to be an incredible catastrophe.
In this article, I’ll share a philosophy that I hope will help programmers overcome the widespread fear of exceptions. It’s motivated by five goals:
- Do no harm
- To write as little error handling code as possible,
- To think about error handling as little as possible
- To handle errors correctly when possible,
- Otherwise errors should be handled sanely
To do that, I
- Use finally to stabilize program state when exceptions are thrown
- Catch and handle exceptions locally when the effects of the error are local and completely understood
- Wrap independent units of work in try-catch blocks to handle errors that have global impact
This isn’t the last word on error handling, but it avoids many of the pitfalls that people fall into with exceptions. By building upon this strategy, I believe it’s possible to develop an effective error handling strategy for most applications: future articles will build on this topic, so keep posted by subscribing to the Generation 5 RSS Feed.
The Tragedy of Checked Exceptions
Java’s done a lot of good, but checked exceptions are probably the worst legacy that Java has left us. Java has influenced Python, PHP, Javascript, C# and many of the popular languages that we use today. Unfortunately, checked exceptions taught Java programmers to catch exceptions prematurely, a habit that Java programmers carried into other languages, and has result in a code base that sets bad examples.
Most exceptions in Java are checked, which means that the compiler will give you an error if you write
[01] public void myMethod() {
[02] throw new ItDidntWorkException()
[03] };
unless you either catch the exception inside myMethod or you replace line [01] with
[04] public void myMethod() throws ItDidntWorkException {
The compiler is also aware of any checked exceptions that are thrown by methods underneath myMethod, and forces you to either catch them inside myMethod or to declare them in the throws clause of myMethod.
I thought that this was a great idea when I started programming Java in 1995. With the hindsight of a decade, we can see that it’s a disaster. The trouble is that every time you call a method that throws an exception, you create an immediate crisis: you break the build. Rather than conciously planning an error handling strategy, programmers do something, anything, to make the compiler shut up. Very often you see people bypass exceptions entirely, like this:
[05] public void someMethod() {
[06] try {
[07] objectA.anotherMethod();
[08] } catch(SubsystemAScrewedUpException ex) { };
[09] }
Often you get this instead:
[10] try {
[11] objectA.anotherMethod();
[12] } catch(SubsystemAScrewedUp ex) {
[13] // something ill-conceived to keep the compiler happy
[14] }
[15] // Meanwhile, the programmer makes a mistake here because
[16] // writing an exception handler broke his concentration
This violates the first principle, to “do no harm.” It’s simple, and often correct, to pass the exception up to the calling function,
[17] public int someMethod() throws SubsystemAScrewedUp {
But, this still breaks the build, because now every function that calls someMethod() needs to do something about the exception. Imagine a program of some complexity that’s maintained by a few programmers, in which method A() calls method B() which calls method C() all the way to method F().
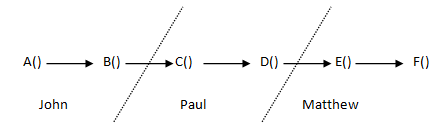
The programmer who works on method F() can change the signature of that method, but he may not have the authority to change the signature of the methods above. Depending on the culture of the shop, he might be able to do it himself, he might talk about it with the other programmers over IM, he might need to get the signatures of three managers, or he might need to wait until the next group meeting. If they keep doing this, however, A() might end up with a signature like
[18] public String A() throws SubsystemAScrewedUp, IOException, SubsystemBScrewedUp, [19] WhateverExceptionVendorZCreatedToWrapANullPointerException, ...
This is getting out of hand, and they realize they can save themselvesa lot of suffering by just writing
[20] public int someMethod() throws Exception {
all the time, which is essentially disabling the checked exception mechanism. Let’s not dismiss the behavior of the compiler out of hand, however, because it’s teaching us an important lesson: error handling is a holistic property of a program: an error handled in method F() can have implications for methods A()…E(). Errors often break the assumption of encapsulation, and require a global strategy that’s applied consistently throughout the code.
PHP, C# and other post-Java languages tend to not support checked exceptions. Unfortunately, checked exception thinking has warped other langages, so you’ll find that catch statements are used neurotically everywhere.
Exception To The Rule: Handling Exceptions Locally
Sometimes you can anticipate an exception, and know what exact action to take. Consider the case of a compiler, or a program that processes a web form, which might find more than one error in user input. Imagine something like (in C#):
[21] List<string> errors=new List<string>();
[22] uint quantity=0;
[23] ... other data fields ...
[24]
[25] try {
[26] quantity=UInt32.Parse(Params["Quantity"]);
[27] } catch(Exception ex) {
[28] errors.Add("You must enter a valid quantity");
[29] }
[30]
[31] ... other parsers/validators ...
[32]
[33] if (errors.Empty()) {
[34] ... update database, display success page ...
[35] } else {
[36] ... redraw form with error messages ...
[37] }
Here it makes sense to catch the exception locally, because the exceptions that can happen on line [22] are completely handled, and don’t have an effect on other parts of the application. The one complaint you might make is that I should be catching something more specific than Exception. Well, that would bulk the code up considerably and violate the DRY (don’t repeat yourself) principle: UInt32.Parse can throw three different exceptions: ArgumentNullException, FormatException, and OverflowException. On paper, the process of looking up the “Quantity” key in Params could throw an ArgumentNullException or a KeyNotFoundException.
I don’t think either ArgumentNullException can really happen, and I think the KeyNotFoundException would only occur in development, or if somebody was trying to submit the HTML form with an unauthorized program. Probably the best thing to do in either case would be to abort the script with a 500 error and log the details, but the error handling on line [24] is sane in that it prevents corruption of the database.
The handling of FormatException and OverflowException, in the other case, is fully correct. The user gets an error message that tells them what they need to do to fix the situation.
This example demonstrates a bit of why error handling is so difficult and why the perfect can be the enemy of the good: the real cause of an IOException could be a microscopic scratch on the surface of a hard drive, and operating system error, or the fact that somebody spilled a coke on a router in Detroit — diagnosing the problem and offering the right solution is an insoluble problem.
Fixing it up with finally
The first exception handling construct that should be on your fingertips is finally, not catch. Unfortunately, finally is a bit obscure: the pattern in most languages is
[38] try {
[39] ... do something that might throw an exception ...
[40] } finally {
[41] ... clean up ...
[42] }
The code in the finally clause get runs whether or not an exception is thrown in the try block. Finally is a great place to release resources, roll back transactions, and otherwise protect the state of the application by enforcing invariants. Let’s think back to the chain of methods A() through F(): with finally, the maintainer of B() can implement a local solution to a global problem that starts in F(): no matter what goes wrong downstream, B() can repair invariants and repair the damage. For instance, if B()’s job is to write something into a transactional data store, B() can do something like:
[43] Transaction tx=new Transaction();
[44] try {
[45] ...
[46] C();
[47] ...
[48] tx.Commit();
[49] } finally {
[50] if (tx.Open)
[51] tx.Rollback();
[52] }
This lets the maintainer of B() act defensively, and offer the guarantee that the persistent data store won’t get corrupted because of an exception that was thrown in the try block. Because B() isn’t catching the exception, it can do this without depriving upstream methods, such as A() from doing the same.
C# gets extra points because it has syntactic sugar that makes a simple case simple: The using directive accepts an IDisposable as an argument and wraps the block after it with a finally clause that calls the Dispose() method of the IDisposable. ASP.NET applications can fail catastrophically if you don’t Dispose() database connections and result sets, so
[53] using (var reader=sqlCommand.ExecuteReader()) {
[54] ... scroll through result set ...
[55] }
is a widespread and effective pattern.
PHP loses points because it doesn’t support finally. Granted, finally isn’t as important in PHP, because all resources are released when a PHP script ends. The absense of finally, however, encourages PHP programmers to overuse catch, which perpetuates exception phobia. The PHP developers are adding great features to PHP 5.3, such as late static binding, so we can hope that they’ll change their mind and bring us a finally clause.
Where should you catch exceptions?
At high levels of your code, you should wrap units of work in a try-catch block. A unit of work is something that makes sense to either give up on or retry. Let’s work out a few simple examples:
Scripty Command line program: This program is going to be used predominantly by the person who wrote it and close associates, so it’s acceptable for the program to print a stack trace if it fails. The “unit of work” is the whole program.
Command line script that processes a million records: It’s likely that some records are corrupted or may trigger bugs in the program. Here it’s reasonable for the “unit of work” to be the processing of a single record. Records that cause exceptions should be logged, together with a stack trace of the exception.
Web application: For a typical web application in PHP, JSP or ASP.NET, the “unit of work” is the web request. Ideally the application returns a “500 Internal Error”, displays a message to the user (that’s useful but not overly revealing) and logs the stack trace (and possibly other information) so the problem can be investigated. If the application is in debugging mode, it’s sane to display the stack trace to the web browser.
GUI application: The “unit of work” is most often an event handler that’s called by the GUI framework. You push a button, something does wrong, then what? Unlike server-side web applications, which tend to assume that exceptions don’t involve corruption of static memory or of a database, GUI applications tend to shut down when they experience unexpected exceptions. [3] As a result, GUI applications tend to need infrastructure to convert common and predictable exceptions (such as network timeouts) into human readable error messages.
Mail server: A mail server stores messages in a queue and delivers them over a unreliable network. Exceptions occur because of full disks (locally or remote), network failures, DNS misconfigurations, remote server falures, and an occasionaly cosmic ray. The “unit of work” is the delivery of a single message. If an exception is thrown during delivery of the message, it stays in the queue: the mail server attempts to resend on a schedule, discarding it if it is unable to deliver after seven days.
What should you do when you’ve caught one?
That’s the subject of another article. Subscribe to my RSS feed if you want to read it when it’s ready. For now, I’ll enumerate a few questions to think about:
- What do tell the end user?
- What do you tell the developer?
- What do you tell the sysadmin?
- Will the error clear if up if we try to repeat this unit of work again?
- How long would we need to wait?
- Could we do something else instead?
- Did the error happen because the state of the application is corrupted?
- Did the error cause the state of the application to get corrupted?
Conclusion
Error handling is tough. Because errors come from many sources such as software defects, bad user input, configuration mistakes, and both permanent and transient hardware failures, it’s impossible for a developer to anticipate and perfectly handle everything that can go wrong. Exceptions are an excellent method of separating error handling logic from the normal flow of programs, but many programmers are too eager to catch exceptions: this either causes errors to be ignores, or entangles error handling with mainline logic, complicating both. The long term impact is that many programmers are afraid of exceptions and turn to return values as an error signals, which is a step backwards.
A strategy that (i) uses finally as the first resort for containing corrupting and maintaining invariants, (ii) uses catch locally when the exceptions thrown in an area are completely understood, and (iii) surrounds independent units of work with try-catch blocks is an effective basis for using exceptions that can be built upon to develop an exception handling policy for a particular application.
Error handling is a topic that I spend entirely too much time thinking about, so I’ll be writing about it more. Subscribe to my RSS Feed if you think I’ve got something worthwhile to say.

Paul Houle on July 31st 2008 in Dot Net, Exceptions, Java, PHP