This article is a follow up to “Don’t Catch Exceptions“, which advocates that exceptions should (in general) be passed up to a “unit of work”, that is, a fairly coarse-grained activity which can reasonably be failed, retried or ignored. A unit of work could be:
- an entire program, for a command-line script,
- a single web request in a web application,
- the delivery of an e-mail message
- the handling of a single input record in a batch loading application,
- rendering a single frame in a media player or a video game, or
- an event handler in a GUI program
The code around the unit of work may look something like
[01] try {
[02] DoUnitOfWork()
[03] } catch(Exception e) {
[04] ... examine exception and decide what to do ...
[05] }
For the most part, the code inside DoUnitOfWork() and the functions it calls tries to throw exceptions upward rather than catch them.
To handle errors correctly, you need to answer a few questions, such as
- Was this error caused by a corrupted application state?
- Did this error cause the application state to be corrupted?
- Was this error caused by invalid input?
- What do we tell the user, the developers and the system administrator?
- Could this operation succeed if it was retried?
- Is there something else we could do?
Although it’s good to depend on existing exception hierarchies (at least you won’t introduce new problems), the way that exceptions are defined and thrown inside the work unit should help the code on line [04] make a decision about what to do — such practices are the subject of a future article, which subscribers to our RSS feed will be the first to read.
The cause and effect of errors
There are a certain range of error conditions that are predictable, where it’s possible to detect the error and implement the correct response. As an application becomes more complex, the number of possible errors explodes, and it becomes impossible or unacceptably expensive to implement explicit handling of every condition.
What do do about unanticipated errors is a controversial topic. Two extreme positions are: (i) an unexpected error could be a sign that the application is corrupted, so that the application should be shut down, and (ii) systems should bend but not break: we should be optimistic and hope for the best. Ultimately, there’s a contradiction between integrity and availability, and different systems make different choices. The ecosystem around Microsoft Windows, where people predominantly develop desktop applications, is inclined to give up the ghost when things go wrong — better to show a “blue screen of death” than to let the unpredictable happen. In the Unix ecosystem, more centered around server applications and custom scripts, the tendency is to soldier on in the face of adversity.
What’s at stake?
Desktop applications tend to fail when unexpected errors happen: users learn to save frequently. Some of the best applications, such as GNU emacs and Microsoft Word, keep a running log of changes to minimize work lost to application and system crashes. Users accept the situation.
On the other hand, it’s unreasonable for a server application that serves hundreds or millions of users to shut down on account of a cosmic ray. Embedded systems, in particular, function in a world where failure is frequent and the effects must be minimized. As we’ll see later, it would be a real bummer if the Engine Control Unit in your car left you stranded home because your oxygen sensor quit working.
The following diagram illustrates the environment of a work unit in a typical application: (although this application accesses network resources, we’re not thinking of it as a distributed application. We’re responsible for the correct behavior of the application running in a single address space, not about the correct behavior of a process swarm.)

The Input to the work unit is a potential source of trouble. The input could be invalid, or it could trigger a bug in the work unit or elsewhere in the system (the “system” encompasses everything in the diagram) Even if the input is valid, it could contain a reference to a corrupted resource, elsewhere in the system. A corrupted resource could be a damaged data structure (such as a colored box in a database), or an otherwise malfunctioning part of the system (a crashed server or router on the network.)
Data structures in the work unit itself are the least problematic, for purposes of error handling, because they don’t outlive the work unit and don’t have any impact on future work units.
Static application data, on the other hand, persists after the work unit ends, and this has two possible consequences:
- The current work unit can fail because a previous work unit caused a resource to be corrupted, and
- The current work unit can corrupt a resource, causing a future work unit to fail
Osterman’s argument that applications should crash on errors is based on this reality: an unanticipated failure is a sign that the application is in an unknown (and possibly bad) state, and can’t be trusted to be reliable in the future. Stopping the application and restarting it clears out the static state, eliminating resource corruption.
Rebooting the application, however, might not free up corrupted resources inside the operating system. Both desktop and server applications suffer from operating system errors from time to time, and often can get immediate relief by rebooting the whole computer.
The “reboot” strategy runs out of steam when we cross the line from in-RAM state to persistent state, state that’s stored on disks, or stored elsewhere on the network. Once resources in the persistent world are corrupted, they need to be (i) lived with, or repaired by (ii) manual or (iii) automatic action.
In either world, a corrupted resource can have either a narrow (blue) or wide (orange) effect on the application. For instance, the user account record of an individual user could be damaged, which prevents that user from logging in. That’s bad, but it would hardly be catastrophic for a system that has 100,000 users. It’s best to ‘ignore’ this error, because a system-wide ‘abort’ would deny service to 99,999 other users; the problem can be corrected when the user complains, or when the problem is otherwise detected by the system administrator.
If, on the other hand, the cryptographic signing key that controls the authentication process were lost, nobody would be able to log in: that’s quite a problem. It’s kind of the problem that will be noticed, however, so aborting at the work unit level (authenticated request) is enough to protect the integrity of the system while the administrators repair the problem.
Problems can happen at an intermediate scope as well. For instance, if the system has damage to a message file for Italian users, people who use the system in the Italian language could be locked out. If Italian speakers are 10% of the users, it’s best to keep the system running for others while you correct the problem.
Repair
There are several tools for dealing with corruption in persistent data stores. In a one-of-a-kind business system, a DBA may need to intervene occasionally to repair corruption. More common events can be handled by running scripts which detect and repair corruption, much like the fsck command in Unix or the chkdsk command in Windows. Corruption in the metadata of a filesystem can, potentially, cause a sequence of events which leads to massive data loss, so UNIX systems have historically run the fsck command on filesystems whenever the filesystem is in a questionable state (such as after a system crash or power failure.) The time do do an fsck has become an increasing burden as disks have gotten larger, so modern UNIX systems use journaling filesystems that protect filesystem metadata with transactional semantics.
Release and Rollback
One role of an exception handler for a unit of work is to take steps to prevent corruption. This involves the release of resources, putting data in a safe state, and, when possible, the rollback of transactions.
Although many kinds of persistent store support transactions, and many in-memory data structures can support transactions, the most common transactional store that people use is the relational database. Although transactions don’t protect the database from all programming errors, they can ensure that neither expected or unexpected exceptions will cause partially-completed work to remain in the database.
A classic example in pseudo code is the following:
[06] function TransferMoney(fromAccount,toAccount,amount) {
[07] try {
[08] BeginTransaction();
[09] ChangeBalance(toAccount,amount);
[10] ... something throws exception here ...
[11] ChangeBalance(fromAccount,-amount);
[12] CommitTransaction();
[13] } catch(Exception e) {
[14] RollbackTransaction();
[15] }
[16] }
In this (simplified) example, we’re transferring money from one bank account to another. Potentially an exception thrown at line [05] could be serious, since it would cause money to appear in toAccount without it being removed from fromAccount. It’s bad enough if this happens by accident, but a clever cracker who finds a way to cause an exception at line [05] has discovered a way to steal money from the bank.
Fortunately we’re doing this financial transaction inside a database transaction. Everything done after BeginTransaction() is provisional: it doesn’t actually appear in the database until CommitTransaction() is called. When an exception happens, we call RollbackTransaction(), which makes it as if the first ChangeBalance() had never been called.
As mentioned in the “Don’t Catch Exceptions” article, it often makes sense to do release, rollback and repairing operations in a finally clause rather than the unit-of-work catch clause because it lets an individual subsystem take care of itself — this promotes encapsulation. However, in applications that use databases transactionally, it often makes sense to push transaction management out the the work unit.
Why? Complex database operations are often composed out of simpler database operations that, themselves, should be done transactionally. To take an example, imagine that somebody is opening a new account and funding it from an existing account:
[17] function OpenAndFundNewAccount(accountInformation,oldAccount,amount) {
[18] if (amount<MinimumAmount) {
[19] throw new InvalidInputException(
[20] "Attempted To Create Account With Balance Below Minimum"
[21] );
[22] }
[23] newAccount=CreateNewAccountRecords(accountInformation);
[24] TransferMoney(oldAccount,newAccount,amount);|
[25] }
It’s important that the TransferMoney operation be done transactionally, but it’s also important that the whole OpenAndFundNewAccount operation be done transactionally too, because we don’t want an account in the system to start with a zero balance.
A straightforward answer to this problem is to always do banking operations inside a unit of work, and to begin, commit and roll back transactions at the work unit level:
[26] AtmOutput ProcessAtmRequest(AtmInput in) {
[27] try {
[28] BeginTransaction();
[29] BankingOperation op=AtmInput.ParseOperation();
[30] var out=op.Execute();
[31] var atmOut=AtmOutput.Encode(out);
[32] CommitTransaction();
[33] return atmOut;
[34] }
[35] catch(Exception e) {
[36] RollbackTransaction();
[37] ... Complete Error Handling ...
[38] }
In this case, there might be a large number of functions that are used to manipulate the database internally, but these are only accessable to customers and bank tellers through a limited set of BankingOperations that are always executed in a transaction.
Notification
There are several parties that could be notified when something goes wrong with an application, most commonly:
- the end user,
- the system administrator, and
- the developers.
Sometimes, as in the case of a public-facing web application, #2 and #3 may overlap. In desktop applications, #2 might not exist.
Let’s consider the end user first. The end user really needs to know (i) that something went wrong, and (ii) what they can do about it. Often errors are caused by user input: hopefully these errors are expected, so the system can tell the user specifically what went wrong: for instance,
[39] try {
[40] ... process form information ...
[41]
[42] if (!IsWellFormedSSN(ssn))
[43] throw new InvalidInputException("You must supply a valid social security number");
[44]
[45] ... process form some more ...
[46] } catch(InvalidInputException e) {
[47] DisplayError(e.Message);
[48] }
other times, errors happen that are unexpected. Consider a common (and bad) practice that we see in database applications: programs that write queries without correctly escaping strings:
[49] dbConn.Execute("
[50] INSERT INTO people (first_name,last_name)
[51] VALUES ('"+firstName+"','+lastName+"');
[52] ");
this code is straightforward, but dangerous, because a single quote in the firstName or lastName variable ends the string literal in the VALUES clause, and enables an SQL injection attack. (I’d hope that you know better than than to do this, but large projects worked on by large teams inevitably have problems of this order.) This code might even hold up well in testing, failing only in production when a person registers with
[53] lastName="O'Reilly";
Now, the dbConn is going to throw something like a SqlException with the following message:
[54] SqlException.Message="Invalid SQL Statement:
[55] INSERT INTO people (first_name,last_name)
[56] VALUES ('Baba','O'Reilly');"
we could show that message to the end user, but that message is worthless to most people. Worse than that, it’s harmful if the end user is a cracker who could take advantage of the error — it tells them the name of the affected table, the names of the columns, and the exact SQL code that they can inject something into. You might be better off showing users something like:

and telling them that they’ve experienced an “Internal Server Error.” Even so, the discovery that a single quote can cause an “Internal Server Error” can be enough for a good cracker to sniff out the fault and develop an attack in the blind.. What can we do? Warn the system administrators. The error handling system for a server application should log exceptions, stack trace and all. It doesn’t matter if you use the UNIX syslog mechanism, the logging service in Windows NT, or something that’s built into your server, like Apache’s error_log. Although logging systems are built into both Java and .Net, many developers find that Log4J and Log4N are especially effective.
There really are two ways to use logs:
- Detailed logging information is useful for debugging problems after the fact. For instance, if a user reports a problem, you can look in the logs to understand the origin of the problem, making it easy to debug problems that occur rarely: this can save hours of time trying to understand the exact problem a user is experiencing.
- A second approach to logs is proactive: to regularly look a logs to detect problems before they get reported. In the example above, the SqlException would probably first be thrown by an innocent person who has an apostrophe in his or her name — if the error was detected that day and quickly fixed, a potential security hole could be fixed long before it would be exploited. Organizaitons that investigate all exceptions thrown by production web applications run the most secure and reliable applications.
In the last decade it’s become quite common for desktop applications to send stack traces back to the developers after a crash: usually they pop up a dialog box that asks for permission first. Although developers of desktop applications can’t be as proactive as maintainers of server applications, this is a useful tool for discovering errors that escape testing, and to discover how commonly they occur in the field.
Retry I: Do it again!
Some errors are transient: that is, if you try to do the same operation later, the operation may succeed. Here are a few common cases:
- An attempt to write to a DVD-R could fail because the disk is missing from the drive
- A database transaction could fail when you commit it because of a conflict with another transaction: an attempt to do the transaction again could succeed
- An attempt to deliver a mail message could fail because of problems with the network or destination mail server
- A web crawler that crawls thousands (or millions) of sites will find that many of them are down at any given time: it needs to deal with this reasonably, rather than drop your site from it’s index because it happened to be down for a few hours
Transient errors are commonly associated with the internet and with remote servers; errors are frequent because of the complexity of the internet, but they’re transitory because problems are repaired by both automatic and human intervention. For instance, if a hardware failure causes a remote web or email server to go down, it’s likely that somebody is going to notice the problem and fix it in a few hours or days.
One strategy for dealing with transient errors is to punt it back to the user: in a case like this, we display an error message that tells the user that the problem might clear up if they retry the operation. This is implicit in how web browsers work: sometimes you try to visit a web page, you get an error message, then you hit reload and it’s all OK. This strategy is particularly effective when the user could be aware that there’s a problem with their internet connection and could do something about it: for instance, they might discover that they’ve moved their laptop out of Wi-Fi range, or that the DSL connection at their house has gone down for the weekend.
SMTP, the internet protocol for email, is one of the best examples of automated retry. Compliant e-mail servers store outgoing mail in a queue: if an attempt to send mail to a destination server fails, mail will stay in the queue for several days before reporting failure to the user. Section 4.5.4 of RFC 2821 states:
The sender MUST delay retrying a particular destination after one attempt has failed. In general, the retry interval SHOULD be at least 30 minutes; however, more sophisticated and variable strategies will be beneficial when the SMTP client can determine the reason for non-delivery. Retries continue until the message is transmitted or the sender gives up; the give-up time generally needs to be at least 4-5 days. The parameters to the retry algorithm MUST be configurable. A client SHOULD keep a list of hosts it cannot reach and corresponding connection timeouts, rather than just retrying queued mail items. Experience suggests that failures are typically transient (the target system or its connection has crashed), favoring a policy of two connection attempts in the first hour the message is in the queue, and then backing off to one every two or three hours.
Practical mail servers use fsync() and other mechanisms to implement transactional semantics on the queue: the needs of reliability make it expensive to run an SMTP-compliant server, so e-mail spammers often use non-compliant servers that don’t correctly retry (if they’re going to send you 20 copies of the message anyway, who cares if only 15 get through?) Greylisting is a highly effective filtering strategy that tests the compliance of SMTP senders by forcing a retry.
Retry II: If first you don’t succeed…
An alternate form of retry is to try something different. For instance, many programs in the UNIX environment will look in many different places for a configuration file: if the file isn’t in the first place tried, it will try the second place and so forth.
The online e-print server at arXiv.org has a system called AutoTex which automatically converts documents written in several dialects of TeX and LaTeX into Postscript and PDF files. AutoTex unpacks the files in a submission into a directory and uses chroot to run the document processing tools in a protected sandbox. It tries about of ten different configurations until it finds one that successfully compiles the document.
In embedded applications, where availability is important, it’s common to fall back to a “safe mode” when normal operation is impossible. The Engine Control Unit in a modern car is a good example:

Since the 1970′s, regulations in the United States have reduced emissions of hydrocarbons and nitrogen oxides from passenger automobiles by more than a hundred fold. The technology has many aspects, but the core of the system in an Engine Control Unit that uses a collection of sensors to monitor the state of the engine and uses this information to adjust engine parameters (such as the quantity of fuel injected) to balance performance and fuel economy with environmental compliance.
As the condition of the engine, driving conditions and composition of fuel change over the time, the ECU normally operates in a “closed-loop” mode that continually optimizes performance. When part of the system fails (for instance, the oxygen sensor) the ECU switches to an “open-loop” mode. Rather than leaving you stranded, it lights the “check engine” indicator and operates the engine with conservative assumptions that will get you home and to a repair shop.
Ignore?
One strength of exceptions, compared to the older return-value method of error handling is that the default behavior of an exception is to abort, not to ignore. In general, that’s good, but there are a few cases where “ignore” is the best option. Ignoring an error makes sense when:
- Security is not at stake, and
- there’s no alternative action available, and
- the consequences of an abort are worse than the consequences of avoiding an error
The first rule is important, because crackers will take advantage of system faults to attack a system. Imagine, for instance, a “smart card” chip embedded in a payment card. People have successfully extracted information from smart cards by fault injection: this could be anything from a power dropout to a bright flash of light on an exposed silicon surface. If you’re concerned that a system will be abused, it’s probably best to shut down when abnormal conditions are detected.
On the other hand, some operations are vestigial to an application. Imagine, for instance, a dialog box that pops when an application crashes that offers the user the choice of sending a stack trace to the vendor. If the attempt to send the stack trace fails, it’s best to ignore the failure — there’s no point in subjecting the user to an endless series of dialog boxes.
“Ignoring” often makes sense in the applications that matter the most and those that matter the least.
For instance, media players and video games operate in a hostile environment where disks, the network, sound and controller hardware are uncooperative. The “unit of work” could be the rendering of an individual frame: it’s appropriate for entertainment devices to soldier on despite hardware defects, unplugged game controllers, network dropouts and corrupted inputs, since the consequences of failure are no worse than shutting the system down.
In the opposite case, high-value systems and high-risk should continue functioning no matter what happen. The software for a space probe, for instance, should never give up. Much like an automotive ECU, space probes default to a “safe mode” when contact with the earth is lost: frequently this strategy involves one or more reboots, but the goal is to always regain contact with controllers so that the mission has a chance at success.
Conclusion
It’s most practical to catch exceptions at the boundaries of relatively coarse “units of work.” Although the handling of errors usually involves some amount of rollback (restoring system state) and notification of affected people, the ultimate choices are still what they were in the days of DOS: abort, retry, or ignore.
Correct handling of an error requires some thought about the cause of an error: was it caused by bad input, corrupted application state, or a transient network failure? It’s also important to understand the impact the error has on the application state and to try to reduce it using mechanisms such as database transactions.
“Abort” is a logical choice when an error is likely to have caused corruption of the application state, or if an error was probably caused by a corrupted state. Applications that depend on network communications sometimes must “Retry” operations when they are interrupted by network failures. Another form of “Retry” is to try a different approach to an operation when the first approach fails. Finally, “Ignore” is appropriate when “Retry” isn’t available and the cost of “Abort” is worse than soldiering on.
This article is one of a series on error handling. The next article in this series will describe practices for defining and throwing exceptions that gives exception handlers good information for making decisions. Subscribers to our RSS Feed will be the first to read it.
]]>It’s clear that a lot of programmers are uncomfortable with exceptions [1] [2]; in the feedback of an article I wrote about casting, it seemed that many programmers saw the throwing of a NullReferenceException at a cast to be an incredible catastrophe.
In this article, I’ll share a philosophy that I hope will help programmers overcome the widespread fear of exceptions. It’s motivated by five goals:
- Do no harm
- To write as little error handling code as possible,
- To think about error handling as little as possible
- To handle errors correctly when possible,
- Otherwise errors should be handled sanely
To do that, I
- Use finally to stabilize program state when exceptions are thrown
- Catch and handle exceptions locally when the effects of the error are local and completely understood
- Wrap independent units of work in try-catch blocks to handle errors that have global impact
This isn’t the last word on error handling, but it avoids many of the pitfalls that people fall into with exceptions. By building upon this strategy, I believe it’s possible to develop an effective error handling strategy for most applications: future articles will build on this topic, so keep posted by subscribing to the Generation 5 RSS Feed.
The Tragedy of Checked Exceptions
Java’s done a lot of good, but checked exceptions are probably the worst legacy that Java has left us. Java has influenced Python, PHP, Javascript, C# and many of the popular languages that we use today. Unfortunately, checked exceptions taught Java programmers to catch exceptions prematurely, a habit that Java programmers carried into other languages, and has result in a code base that sets bad examples.
Most exceptions in Java are checked, which means that the compiler will give you an error if you write
[01] public void myMethod() {
[02] throw new ItDidntWorkException()
[03] };
unless you either catch the exception inside myMethod or you replace line [01] with
[04] public void myMethod() throws ItDidntWorkException {
The compiler is also aware of any checked exceptions that are thrown by methods underneath myMethod, and forces you to either catch them inside myMethod or to declare them in the throws clause of myMethod.
I thought that this was a great idea when I started programming Java in 1995. With the hindsight of a decade, we can see that it’s a disaster. The trouble is that every time you call a method that throws an exception, you create an immediate crisis: you break the build. Rather than conciously planning an error handling strategy, programmers do something, anything, to make the compiler shut up. Very often you see people bypass exceptions entirely, like this:
[05] public void someMethod() {
[06] try {
[07] objectA.anotherMethod();
[08] } catch(SubsystemAScrewedUpException ex) { };
[09] }
Often you get this instead:
[10] try {
[11] objectA.anotherMethod();
[12] } catch(SubsystemAScrewedUp ex) {
[13] // something ill-conceived to keep the compiler happy
[14] }
[15] // Meanwhile, the programmer makes a mistake here because
[16] // writing an exception handler broke his concentration
This violates the first principle, to “do no harm.” It’s simple, and often correct, to pass the exception up to the calling function,
[17] public int someMethod() throws SubsystemAScrewedUp {
But, this still breaks the build, because now every function that calls someMethod() needs to do something about the exception. Imagine a program of some complexity that’s maintained by a few programmers, in which method A() calls method B() which calls method C() all the way to method F().
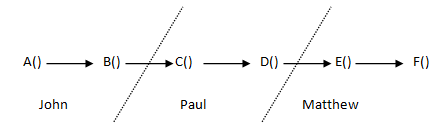
The programmer who works on method F() can change the signature of that method, but he may not have the authority to change the signature of the methods above. Depending on the culture of the shop, he might be able to do it himself, he might talk about it with the other programmers over IM, he might need to get the signatures of three managers, or he might need to wait until the next group meeting. If they keep doing this, however, A() might end up with a signature like
[18] public String A() throws SubsystemAScrewedUp, IOException, SubsystemBScrewedUp, [19] WhateverExceptionVendorZCreatedToWrapANullPointerException, ...
This is getting out of hand, and they realize they can save themselvesa lot of suffering by just writing
[20] public int someMethod() throws Exception {
all the time, which is essentially disabling the checked exception mechanism. Let’s not dismiss the behavior of the compiler out of hand, however, because it’s teaching us an important lesson: error handling is a holistic property of a program: an error handled in method F() can have implications for methods A()…E(). Errors often break the assumption of encapsulation, and require a global strategy that’s applied consistently throughout the code.
PHP, C# and other post-Java languages tend to not support checked exceptions. Unfortunately, checked exception thinking has warped other langages, so you’ll find that catch statements are used neurotically everywhere.
Exception To The Rule: Handling Exceptions Locally
Sometimes you can anticipate an exception, and know what exact action to take. Consider the case of a compiler, or a program that processes a web form, which might find more than one error in user input. Imagine something like (in C#):
[21] List<string> errors=new List<string>();
[22] uint quantity=0;
[23] ... other data fields ...
[24]
[25] try {
[26] quantity=UInt32.Parse(Params["Quantity"]);
[27] } catch(Exception ex) {
[28] errors.Add("You must enter a valid quantity");
[29] }
[30]
[31] ... other parsers/validators ...
[32]
[33] if (errors.Empty()) {
[34] ... update database, display success page ...
[35] } else {
[36] ... redraw form with error messages ...
[37] }
Here it makes sense to catch the exception locally, because the exceptions that can happen on line [22] are completely handled, and don’t have an effect on other parts of the application. The one complaint you might make is that I should be catching something more specific than Exception. Well, that would bulk the code up considerably and violate the DRY (don’t repeat yourself) principle: UInt32.Parse can throw three different exceptions: ArgumentNullException, FormatException, and OverflowException. On paper, the process of looking up the “Quantity” key in Params could throw an ArgumentNullException or a KeyNotFoundException.
I don’t think either ArgumentNullException can really happen, and I think the KeyNotFoundException would only occur in development, or if somebody was trying to submit the HTML form with an unauthorized program. Probably the best thing to do in either case would be to abort the script with a 500 error and log the details, but the error handling on line [24] is sane in that it prevents corruption of the database.
The handling of FormatException and OverflowException, in the other case, is fully correct. The user gets an error message that tells them what they need to do to fix the situation.
This example demonstrates a bit of why error handling is so difficult and why the perfect can be the enemy of the good: the real cause of an IOException could be a microscopic scratch on the surface of a hard drive, and operating system error, or the fact that somebody spilled a coke on a router in Detroit — diagnosing the problem and offering the right solution is an insoluble problem.
Fixing it up with finally
The first exception handling construct that should be on your fingertips is finally, not catch. Unfortunately, finally is a bit obscure: the pattern in most languages is
[38] try {
[39] ... do something that might throw an exception ...
[40] } finally {
[41] ... clean up ...
[42] }
The code in the finally clause get runs whether or not an exception is thrown in the try block. Finally is a great place to release resources, roll back transactions, and otherwise protect the state of the application by enforcing invariants. Let’s think back to the chain of methods A() through F(): with finally, the maintainer of B() can implement a local solution to a global problem that starts in F(): no matter what goes wrong downstream, B() can repair invariants and repair the damage. For instance, if B()’s job is to write something into a transactional data store, B() can do something like:
[43] Transaction tx=new Transaction();
[44] try {
[45] ...
[46] C();
[47] ...
[48] tx.Commit();
[49] } finally {
[50] if (tx.Open)
[51] tx.Rollback();
[52] }
This lets the maintainer of B() act defensively, and offer the guarantee that the persistent data store won’t get corrupted because of an exception that was thrown in the try block. Because B() isn’t catching the exception, it can do this without depriving upstream methods, such as A() from doing the same.
C# gets extra points because it has syntactic sugar that makes a simple case simple: The using directive accepts an IDisposable as an argument and wraps the block after it with a finally clause that calls the Dispose() method of the IDisposable. ASP.NET applications can fail catastrophically if you don’t Dispose() database connections and result sets, so
[53] using (var reader=sqlCommand.ExecuteReader()) {
[54] ... scroll through result set ...
[55] }
is a widespread and effective pattern.
PHP loses points because it doesn’t support finally. Granted, finally isn’t as important in PHP, because all resources are released when a PHP script ends. The absense of finally, however, encourages PHP programmers to overuse catch, which perpetuates exception phobia. The PHP developers are adding great features to PHP 5.3, such as late static binding, so we can hope that they’ll change their mind and bring us a finally clause.
Where should you catch exceptions?
At high levels of your code, you should wrap units of work in a try-catch block. A unit of work is something that makes sense to either give up on or retry. Let’s work out a few simple examples:
Scripty Command line program: This program is going to be used predominantly by the person who wrote it and close associates, so it’s acceptable for the program to print a stack trace if it fails. The “unit of work” is the whole program.
Command line script that processes a million records: It’s likely that some records are corrupted or may trigger bugs in the program. Here it’s reasonable for the “unit of work” to be the processing of a single record. Records that cause exceptions should be logged, together with a stack trace of the exception.
Web application: For a typical web application in PHP, JSP or ASP.NET, the “unit of work” is the web request. Ideally the application returns a “500 Internal Error”, displays a message to the user (that’s useful but not overly revealing) and logs the stack trace (and possibly other information) so the problem can be investigated. If the application is in debugging mode, it’s sane to display the stack trace to the web browser.
GUI application: The “unit of work” is most often an event handler that’s called by the GUI framework. You push a button, something does wrong, then what? Unlike server-side web applications, which tend to assume that exceptions don’t involve corruption of static memory or of a database, GUI applications tend to shut down when they experience unexpected exceptions. [3] As a result, GUI applications tend to need infrastructure to convert common and predictable exceptions (such as network timeouts) into human readable error messages.
Mail server: A mail server stores messages in a queue and delivers them over a unreliable network. Exceptions occur because of full disks (locally or remote), network failures, DNS misconfigurations, remote server falures, and an occasionaly cosmic ray. The “unit of work” is the delivery of a single message. If an exception is thrown during delivery of the message, it stays in the queue: the mail server attempts to resend on a schedule, discarding it if it is unable to deliver after seven days.
What should you do when you’ve caught one?
That’s the subject of another article. Subscribe to my RSS feed if you want to read it when it’s ready. For now, I’ll enumerate a few questions to think about:
- What do tell the end user?
- What do you tell the developer?
- What do you tell the sysadmin?
- Will the error clear if up if we try to repeat this unit of work again?
- How long would we need to wait?
- Could we do something else instead?
- Did the error happen because the state of the application is corrupted?
- Did the error cause the state of the application to get corrupted?
Conclusion
Error handling is tough. Because errors come from many sources such as software defects, bad user input, configuration mistakes, and both permanent and transient hardware failures, it’s impossible for a developer to anticipate and perfectly handle everything that can go wrong. Exceptions are an excellent method of separating error handling logic from the normal flow of programs, but many programmers are too eager to catch exceptions: this either causes errors to be ignores, or entangles error handling with mainline logic, complicating both. The long term impact is that many programmers are afraid of exceptions and turn to return values as an error signals, which is a step backwards.
A strategy that (i) uses finally as the first resort for containing corrupting and maintaining invariants, (ii) uses catch locally when the exceptions thrown in an area are completely understood, and (iii) surrounds independent units of work with try-catch blocks is an effective basis for using exceptions that can be built upon to develop an exception handling policy for a particular application.
Error handling is a topic that I spend entirely too much time thinking about, so I’ll be writing about it more. Subscribe to my RSS Feed if you think I’ve got something worthwhile to say.

The first language I used that put dictionaries on my fingertips was Perl, where the solution to just about any problem involved writing something like
$hashtable{$key}=$value;
Perl called a dictionary a ‘hash’, a reference to the way Perl implemented dictionaries. (Dictionaries are commonly implemented with hashtables and b-trees, but can also be implemented with linked-list and other structures.) The syntax of Perl is a bit odd, as you’d need to use $, # or % to reference scalar, array or hash variables in different contexts, but dictionaries with similar semantics became widespread in dynamic languages of that and succeeding generations, such as Python, PHP and Ruby. ‘Map’ container classes were introduced in Java about a decade ago, and programmers are using dictionaries increasingly in static languages such as Java and C#.
Dictionaries are a convenient and efficient data structure, but there’s are areas in which different mplementations behave differently: for instance, in what happens if you try to access an undefined key. I think that cross-training is good for developers, so this article compares this aspect of the semantics of dictionaries in four popular languages: PHP, Python, Java and C#.
Use cases
There are two use cases for dictionaries, so far as error handling is concerned:
- When you expect to look up undefined values, and
- When you don’t
Let’s look at three examples:
Computing A Histogram
One common use for a dictionary is for counting items, or recording that items in a list or stream have been seen. In C#, this is typically written something like:
[01] var count=Dictionary<int,int>();
[02] foreach(int i in inputList) {
[03] if (!counts.Contains(i))
[04] count[i]=0;
[05]
[06] count[i]=count[i]+1
[07] }
The Dictionary count now contains the frequency of items inputList, which could be useful for plotting a histogram. A similar pattern can be used if we wish to make a list of unique items found in inputList. In either case, looking up values that aren’t already in the hash is a fundamental part of the algorithm.
Processing Input
Sometimes, we’re getting input from another subsystem, and expect that some values might not be defined. For instance, suppose a web site has a search feature with a number of optional features, and that queries are made by GET requests like:
[08] search.php?q=kestrel [09] search.php?q=admiral&page=5 [10] search.php?q=laurie+anderson&page=3&in_category=music&after_date=1985-02-07
In this case, the only required search parameter is “q”, the query string — the rest are optional. In PHP (like many other environments), you can get at GET variables via a hashtable, specifically, the $_GET superglobal, so (depending on how strict the error handling settings in your runtime are) you might write something like
[11] if ($_GET["q"])) {
[12] throw new InvalidInputException("You must specify a query");
[13] }
[14]
[15] if($_GET["after_date"]) {
[16] ... add another WHERE clause to a SQL query ...
[17] }
This depends, quite precisely, on two bits of sloppiness in PHP and Perl: (a) Dereferencing an undefined key on a hash returns an undefined value, which is something like a null. (b) both languages have a liberal definition of true and false in an if() statement. As a result, the code above is a bit quirky. The if() at line 11 evaluates false if q is undefined, or if q is the empty string. That’s good. However, both the numeric value 0 and the string “0″ also evaluate false. As a result, this code won’t allow a user to search for “0″, and will ignore an (invalid) after_date of 0, rather than entering the block at line [16], which hopefully would validate the date.
Java and C# developers might enjoy a moment of schadenfreude at the above example, but they’ve all seen, written and debugged examples of input handling code that just as quirky as the above PHP code — with several times the line count. To set the record straight, PHP programmers can use the isset() function to precisely test for the existence of a hash key:
[11] if (isset($_GET["q"]))) {
[12] throw new InvalidInputException("You must specify a query");
[13] }
The unusual handling of “0″ is the kind of fault that can survive for years in production software: so long as nobody searches for “0″, it’s quite harmless. (See what you get if you search for a negative integer on Google.) The worst threat that this kind of permissive evaluation poses is when it opens the door to a security attack, but we’ve also seen that highly complex logic that strives to be “correct” in every situation can hide vulnerabilities too.
Relatively Rigid Usage
Let’s consider a third case: passing a bundle of context in an asynchronous communications call in a Silverlight application written in C#. You can do a lot worse than to use the signatures:
[14] void BeginAsyncCall(InputType input,Dictionary<string, object> context,CallbackDelegate callback); [15] void CallbackDelegate(ReturnType returnValue,Dictionary<string,object> context);
The point here is that the callback might need to know something about the context in which the asynchronous function was called to do it’s work. However, this information may be idiosyncratic to the particular context in which the async function is called, and is certainly not the business of the asynchronous function. You might write something like
[16] void Initiator() {
[17] InputType input=...;
[18] var context=Dictionary<string,object>();
[19] context["ContextItemOne"]= (TypeA) ...;
[20] context["ContextItemTwo"]= (TypeB) ...;
[21] context["ContextItemThre"] = (TypeC) ...;
[22] BeginAsyncCall(input,context,TheCallback);
[23] }
[24]
[25] void TheCallback(ReturnType output,Dictionary<string,object> context) {
[26] ContextItemOne = (TypeA) context["ContextItemOne"];
[27] ContextItemTwo = (TypeB) context["ContextItemTwo"];
[28] ContextItemThree = (TypeC) context["ContextItemThree"];
[29] ...
[30] }
This is nice, isn’t it? You can pass any data values you want between Initiator and TheCallback. Sure, the compiler isn’t checking the types of your arguments, but loose coupling is called for in some situations. Unfortunately it’s a little too loose in this case, because we spelled the name of a key incorrectly on line 21.
What happens?
The [] operator on a dot-net Dictionary throws a KeyNotFoundException when we try to look up a key that doesn’t exist. I’ve set a global exception handler for my Silverlight application which, in debugging mode, displays the stack trace. The error gets quickly diagnosed and fixed.
Four ways to deal with a missing value
There are four tools that hashtables give programmers to access values associated with keys and detect missing values:
- Test if key exists
- Throw exception if key doesn’t exist
- Return default value (or null) if key doesn’t exist
- TryGetValue
#1: Test if key exists
PHP: isset($hashtable[$key]) Python: key in hashtable C#: hashtable.Contains(key) Java: hashtable.containsKey(key)
This operator can be used together with the #2 or #3 operator to safely access a hashtable. Line [03]-[04] illustrates a common usage pattern.
One strong advantage of the explicit test is that it’s more clear to developers who spend time working in different language environments — you don’t need to remember or look in the manual to know if the language you’re working in today uses the #2 operator or the #3 operator.
Code that depends on the existence test can be more verbose than alternatives, and can be structurally unstable: future edits can accidentally change the error handling properties of the code. In multithreaded environments, there’s a potential risk that an item can be added or removed between the existance check and an access — however, the default collections in most environment are not thread-safe, so you’re likely to have worse problems if a collection is being accessed concurrently.
#2 Throw exception if key doesn’t exist
Python: hashtable[key] C#: hashtable[key]
This is a good choice when the non-existence of a key is really an exceptional event. In that case, the error condition is immediately propagated via the exception handling mechanism of the language, which, if properly used, is almost certainly better than anything you’ll develop. It’s awkward, and probably inefficient, if you think that non-existent keys will happen frequently. Consider the following rewrite of the code between [01]-[07]
[31] var count=Dictionary<int,int>();
[32] foreach(int i in inputList) {
[33] int oldCount;
[34] try {
[35] oldCount=count[i];
[36] } catch (KeyNotFoundException ex) {
[37] oldCount=0
[38] }
[39]
[40] count[i]=oldCount+1
[41] }
It may be a matter of taste, but I think that’s just awful.
#3 Return a default (often null) value if key doesn’t exist
PHP: $hashtable[key] (well, almost) Python: hashtable.get(key, [default value]) Java: hashtable.get(key)
This can be a convenient and compact operation. Python’s form is particularly attractive because it lets us pick a specific default value. If we use an extension method to add a Python-style GetValue operation in C#, the code from [01]-[07] is simplified to
[42] var count=Dictionary<int,int>(); [43] foreach(int i in inputList) [44] count[i]=count.GetValue(i,0)+1;
It’s reasonable for the default default value to be null (or rather, the default value of the type), as it is in Python, in which case we could use the ??-operator to write
[42] var count=Dictionary<int,int>(); [43] foreach(int i in inputList) [44] count[i]=(count.GetValue(i) ?? 0)+1;
(A ?? B equals A if A is not null, otherwise it equals B.) The price for this simplicity is two kinds of sloppiness:
- We can’t tell the difference between a null (or default) value associated with a key and no value associated with a key
- The potential of null value exports chaos into the environment: trying to use a null value can cause a NullReferenceException if we don’t explictly handle the null. NullReferenceExceptions don’t bother me if they happen locally to the function that returns them, but they can be a bear to understand when a null gets written into an instance variable that’s accessed much later.
Often people don’t care about 1, and the risk of 2 can be handled by specifying a non-null default value.
Note that PHP’s implementation of hashtables has a particularly annoying characteristic. Error handling in php is influenced by the error_reporting configuration variable which can be set in the php.ini file and other places. If the E_STRICT bit is not set in error_reporting, PHP barrels on past places where incorrect variable names are used:
[45] $correctVariableName="some value";
[46] echo "[{$corectValiableName}]"; // s.i.c.
In that case, the script prints “[]” (treats the undefined variable as an empty string) rather than displaying an error or warning message. PHP will give a warning message if E_STRICT is set, but then it applies the same behavior to hashtables: an error message is printed if you try to dereference a key that doesn’t exist — so PHP doesn’t consistently implement type #3 access.
#4 TryGetValue
There are quite a few methods (Try-* methods) in the .net framework that have a signature like this:
[47] bool Dictionary<K,V>.TryGetValue(K key,out V value);
This method has crisp and efficient semantics which could be performed in an atomic thread-safe manner: it returns true if finds the key, and otherwise returns false. The output parameter value is set to the value associated with the key if a value is associated with the key, however, I couldn’t find a clear statement of what happens if the key isn’t found. I did a little experiment:
[48] var d = new Dictionary<int, int>(); [49] d[1] = 5; [50] d[2] = 7; [51] int outValue = 99; [52] d.TryGetValue(55, out outValue) [53] int newValue = outValue;
I set a breakpoint on line 53 and found thate the value of outValue was 0, which is the default value of the int type. It seems, therefore, that TryGetValue returns the default value of the type when it fails to find the key. I wouldn’t count on this behavior, as it is undocumented.
The semantics of TryGetValue are crisp and precise. It’s particularly nice that something like TryGetValue could be implemented as an atomic operation, if the underyling class is threadsafe. I fear, however, that TryGetValue exports chaos into it’s environment. For instance, I don’t like declaring a variable without an assignment, like below:
[54] int outValue;
[55] if (d.TryGetValue(55,outValue)) {
[56] ... use outValue ...
[57] }
The variable outValue exists before the place where it’s set, and outside of the block where it has a valid value. It’s easy for future maintainers of the code to try to use outValue between lines [54]-[55] or after line [57]. It’s also easy to write something like 51], where the value 99 is completely irrelevant to the program. I like the construction
[58] if (d.Contains(key)) {
[59] int value=d[key];
[60] ... do something with value ...
[61] }
because the variable value only exists in the block [56]-[58] where it has a defined value.
Hacking Hashables
A comparison of hashtables in different languages isn’t just academic. If you don’t like the operations that your language gives you for hashtables, you’re free to implement new operations. Let’s take two simple examples. It’s nice to have a Python-style get() in PHP that never gives a warning message, and it’s easy to implement
[62] function array_get($array,$key,$defaultValue=false) {
[63] if (!isset($array[$key]))
[64] return $defaultValue;
[65]
[66] return $array[$key];
[67] }
Note that the third parameter of this function uses a default value of false, so it’s possible to call it in a two-parameter form
[68] $value=array_get($array,$key);
with a default default of false, which is reasonable in PHP.
Extension methods make it easy to add a Python-style get() to C#; I’m going to call it GetValue() to be consistent with TryGetValue():
[69] public static class DictionaryExtensions {
[70] public static V GetValue<K, V>(this IDictionary<K, V> dict, K key) {
[71] return dict.GetValue(key, default(V));
[72] }
[73]
[74] public static V GetValue<K, V>(this IDictionary<K, V> dict, K key, V defaultValue) {
[75] V value;
[76] return dict.TryGetValue(key, out value) ? value : defaultValue;
[77] }
[78] }
Conclusion
Today’s programming languages put powerful data structures, such as dictionaries, on your fingertips. When we look closely, we see subtle differences in the APIs used access dictionaries in different languages. A study of the different APIs and their consequences can help us think about how to write code that is more reliable and maintainable, and informs API design in every language

int AddToCount(int amount,string countId) {
int countValue=GetCount(countId);
return countValue+amount;
}
This doesn’t work if the GetCount function is asynchronous, where we need to write something like
int AddToCountBegin(int amount,string countId,CountCallback outerCallback) {
GetCountBegin(countId,AddToCountCallback);
}
void AddToCountCallback(int countValue) {
... some code to get the values of amount and outerCallback ...
outerCallback(countValue+amount);
}
Several things change in this example: (i) the AddToCount function gets broken up into two functions: one that does the work before the GetCount invocation, and one that does the work after GetCount completes. (ii) We can’t return a meaningful value from AddToCountCallback, so it needs to ‘return’ a value via a specified callback function. (iii) Finally, the values of outerCallback and amount aren’t automatically shared between the functions, so we need to make sure that they are carried over somehow.
There are three ways of passing context from a function that calls and asynchronous function to the callback function:
- As an argument to the callback function
- As an instance variable of the class of which the callback function is a class
- Via a closure
Let’s talk about these alternatives:
1. Argument to the Callback Function
In this case, a context object is passed to the asynchronous function, which passes the context object to the callback. The advantage here is that there aren’t any constraints on how the callback function is implemented, other than by accepting the context object as a callback. In particular, the callback function can be static. A major disadvantage is that the asynchronous function has to support this: it has to accept a state object which it later passes to the callback function.
The implementation of HttpWebRequest.BeginGetResponse(AsyncCallback a,Object state) in the Silverlight libraries is a nice example. If you wish to pass a context object to the AsyncCallback, you can pass it in the second parameter, state. Your callback function will implement the AsyncCallback delegate, and will get something that implements IAsyncResult as a parameter. The state that you passed into BeginGetResponse will come back in the IAsyncResult.AsyncState property. For example:
class MyHttpContext {
public HttpWebRequest Request;
public SomeObject FirstContextParameter;
public AnotherObject AnotherContextParameter;
}
protected void myHttpCallback(IAsyncResult abstractResult) {
MyHttpContext context = (MyHttpContext) abstractResult.AsyncState;
HttpWebResponse Response=(HttpWebResponse) context.Request.EndGetResponse(abstractResult);
}
public doHttpRequest(...) {
...
MyHttpContext context=new MyHttpContext();
context.Request=Request;
context.FirstContextParameter = ... some value ...;
context.AnotherContextParameter = .. another value ...;
Request.BeginGetResponse();
Request.Callback(myHttpCallback,context);
}
Note that, in this API, the Request object needs to be available in myHttpCallback because myHttpCallbacks get the response by calling the HttpWebResponse.EndGetResponse() method. We could simply pass the Request object in the state parameter, but we’re passing an object we defined, myHttpCallback, because we’d like to carry additional state into myHttpCallback.
Note that the corresponding method for doing XMLHttpRequests in GWT, the use of a RequestBuilder object doesn’t allow using method (1) to pass context information — there is no state parameter. in GWT you need to use method (2) or (3) to pass context at the RequestBuilder or GWT RPC level. You’re free, of course, to use method (1) when you’re chaining asynchronous callbacks: however, method (2) is more natural in Java where, instead of a delegate, you need to pass an object reference to designate a callback function.
2. Instance Variable Of The Callback Function’s Class
Functions (or Methods) are always attached to a class in C# and Java: thus, the state of a callback function can be kept in either static or instance variables of the associated class. I don’t advise using static variables for this, because it’s possible for more than one asynchronous request to be flight at a time: if two request store state in the same variables, you’ll introduce race conditions that will cause a world of pain. (see how race conditions arise in asynchronous communications.)
Method 2 is particularly effective when both the calling and the callback functions are methods of the same class. Using objects whose lifecycle is linked to a single asynchronous request is an effective way to avoid conflicts between requests (see the asynchronous command pattern and asynchronous functions.)
Here’s an example, lifted from the asynchronous functions article:
public class HttpGet : IAsyncFunction<String>
{
private Uri Path;
private CallbackFunction<String> OuterCallback;
private HttpWebRequest Request;
public HttpGet(Uri path)
{
Path = path;
}
public void Execute(CallbackFunction<String> outerCallback)
{
OuterCallback = outerCallback;
try
{
Request = (HttpWebRequest)WebRequest.Create(Path);
Request.Method = "GET";
Request.BeginGetRequestStream(InnerCallback,null);
}
catch (Exception ex)
{
OuterCallback(CallbackReturnValue<String>.CreateError(ex));
}
}
public void InnerCallback(IAsyncResult result)
{
try
{
HttpWebResponse response = (HttpWebResponse) Request.EndGetResponse(result);
TextReader reader = new StreamReader(response.GetResponseStream());
OuterCallback(CallbackReturnValue<String>.CreateOk(reader.ReadToEnd()));
} catch(Exception ex) {
OuterCallback(CallbackReturnValue<String>.CreateError(ex));
}
}
}
Note that two pieces of context are being passed into the callback function: an HttpWebRequest object named Request (necessary to get the response) and a CallbackFunction<String> delegate named OuterCallback that receives the return value of the asynchronous function.
Unlike Method 1, Method 2 makes it possible to keep an unlimited number of context variables that are unique to a particular case in a manner that is both typesafe and oblivious to the function being called — you don’t need to cast an Object to something more specific, and you don’t need to create a new class to hold multiple variables that you’d like to pass into the callback function.
Method 2 comes into it’s own when it’s used together with polymorphism, inheritance and initialization patterns such as the factory pattern: if the work done by the requesting and callback methods can be divided into smaller methods, a hierarchy of asynchronous functions or commands can reuse code efficiently.
3. Closures
In both C# and Java, it’s possible for a method defined inside a method to have access to variables in the enclosing method. In C# this is a matter of creating an anonymous delegate, while in Java it’s necessary to create an anonymous class.
Using closures results in the shortest code, if not the most understandable code. In some cases, execution proceeds in a straight downward line through the code — much like a synchronous version of the code. However, people sometimes get confused the indentation, and, more seriously, parameters after the closure definition and code that runs immediately after the request is fired end up in an awkward place (after the definition of the callback function.)
public class HttpGet : IAsyncFunction<String>
{
private Uri Path;
public HttpGet(Uri path)
{
Path = path;
}
public void Execute(CallbackFunction<String> outerCallback)
{
OuterCallback = outerCallback;
try
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(Path);
Request.Method = "GET";
Request.BeginGetRequestStream(delegate(IAsyncResult result) {
try {
response = request.EndGetResponse(result);
TextReader reader = new StreamReader(response.GetResponseStream());
outerCallback(CallbackReturnValue<String>.CreateOk(reader.ReadToEnd()));
} catch(Exception ex) {
outerCallback(CallbackReturnValue<String>.CreateError(ex));
}
},null); // <--- note parameter value after delegate definition
}
catch (Exception ex)
{
outerCallback(CallbackReturnValue<String>.CreateError(ex));
}
}
}
The details are different in C# and Java: anonymous classes in Java can access local, static and instance variables from the enclosing context that are declared final — this makes it impossible for variables to be stomped on while an asynchronous request is in flight. C# closures, on the other hand, can access only local variables: most of the time this prevents asynchronous requests from interfering with one another, unless a single method fires multiple asynchronous requests, in which case counter-intuitive things can happen.
Conclusion
In addition to receiving return value(s), callback functions need to know something about the context they run in: to write reliable applications, you need to be conscious of where this information is; better yet, a strategy for where you’re going to put it. Closures, created with anonymous delegates (C#) or classes (Java) produce the shortest code, but not necessarily the clearest. Passing context in an argument to the callback function requires the cooperation of the called function, but it makes few demands on the calling and callback functions: the calling and callback functions can both be static. When a single object contains both calling and callback functions, context can be shared in a straightforward and typesafe manner; and when the calling and callback functions can be broken into smaller functions, opportunities for efficient code reuse abound.

There’s a lot of confusion about how asynchronous communication works in RIA’s such as Silverlight, GWT and Javascript. When I start talking about the problems of concurrency control, many people tell me that there aren’t any concurrency problems since everything runs in a single thread. [1]
It’s important to understand the basics of what is going on when you’re writing asynchronous code, so I’ve put together a simple example to show how execution works in RIA’s and how race conditions are possible. This example applies to Javascript, Silverlight, GWT and Flex, as well as a number of other environments based on Javascript. This example doesn’t represent best practices, but rather what can happen when you’re not using a proactive strategy that eliminates concurrency problems:
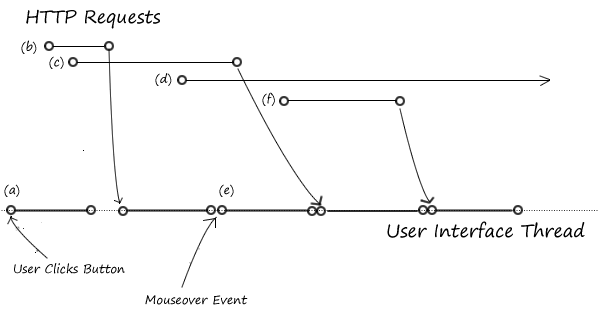
In the diagram above, execution starts when the user pushes a button (a). This starts the user interface thread by invoking an onClick handler. The user interface thread starts two XmlHttpRequests, (b) and (c). The event handler eventually returns, so execution stops in the user interface thread.
In the meantime, the browser still has two XmlHttpRequests running. Callbacks from http requests, timers and user interfaces go into a queue — they get executed right away if the user interface thread is doing nothing, but get delayed if the user interface thread is active.
Http request (b) completes first, causing the http callback for request (b) to start. Had something been a little different with the web browser, web server or network, request (c) could have returned first, causing the callback for request (c) to start. If the result of the program depends on the order that the callbacks for (b) and (c) run, we have a race condition. The callback for http request (b) starts a new http request (d), which runs for a long time.
In the meantime, the user is moving the mouse and triggers a mouseover event while the request (b) callback is running. Right after the request (b) callback completes, the web browser starts the UI thread, which causes a mouseover event handler (e) to run. Note that the user can trigger user interface events while XmlHttpRequests are running, causing event handlers to run in an unpredictable order: if this causes your program to malfunction, your program has a bug.
While the event handler (e) is running, request (c) completes: like the mouseover event, this event is queued and runs once event handler (e) completes. Before (e) completes, it starts a new http request (f). The browser looks into the event queue when (e) completes, and starts the callback for (c). Http request (f) completes while callback (c) is running, gets queued, and runs after (c) is running.
At the end of this example, the callback for (f) completes, causing the UI thread to stop. The http request (c) is still in flight — it completes in the future, somewhere off the end of the page.
This example did not include any timers, or any mechanism of deferred execution such as DeferredCommand in GWT or Dispatcher.Invoke() in Silverlight. This is but another mechanism to add callback references to the event queue.
As you can see, there’s a lot of room for mischief: http requests can return in an arbitrary order and users can initiate events at arbitrary times. The order that things happen in can depend on the browser, it’s settings, on the behavior of the server, and everything in between. Some users might use the application in a way that avoids certain problems (they’ll think it’s wonderful) and others might consistently or occasionally trigger an event that causes catastrophe. These kind of bugs can be highly difficult to reproduce and repair.
Asynchronous RIAs have problems with race conditions that are similar to threaded applications, but not exactly the same. Today’s languages and platforms have excellent and well documented mechanisms for dealing with threads, but today’s RIAs do not have mature mechanisms for dealing with concurrency. Over time we’ll see libraries and frameworks that help, but asynchronous safety isn’t something that can be applied like deodorant: it involves non local interactions between distant parts of the program. The simplest applications can dodge the bullet, but applications beyond a certain level of complexity require an understanding of asynchronous execution and the consistent use of patterns that avoid trouble.
[1] Although it is possible to create new threads in Silverlight, all communication and user interface access must be done from the user interface thread — many Silverlight applications are single-threaded, and adding multiple threads complicates the issue.
]]> void CallingMethod(...) {
... do some things ...
IAsyncFunction<String> httpGet=new HttpGet(... parameters...);
anAsynchronousFunction.Execute(CallbackMethod);
}
void CallbackMethod(CallbackReturnValue<String> crv) {
if (crv.Error!=null) { ... handle Error, which is an Exception ...}
String returnValue=crv.Value;
... do something with the return value ...
}
We’re using generics so that return values can be passed back in a type safe manner. The type of the return value of the asynchronous function is specified in the type parameter of IAsyncFunction and CallbackReturnValue.
Asynchronous functions catch exceptions and pass them back in in the CallbackReturnValue. This makes it possible to propagate exceptions back to the caller, as in synchronous functions. The code to do this must has to be manually replicated in each asynchronous function, however, the code can be put into a wrapper delegate.
You could do the same thing in Java, but the CallbackMethod would need to be a class that implements an interface rather than a delegate.
In C# it takes one class, one interface and one delegate to make this work:
public delegate void CallbackFunction<ReturnType>(CallbackReturnValue<ReturnType> value);
public class CallbackReturnValue<ReturnType> {
public ReturnType Value {get; private set; }
public Exception Error {get; private set; }
protected CallbackReturnValue() { }
public static CallbackReturnValue<ReturnType> CreateOk(ReturnType value) {
CallbackReturnValue<ReturnType> crv=new CallbackReturnValue<ReturnType>();
crv.Value=value;
return crv;
}
public static CallbackReturnValue<ReturnType> CreateError(Exception error) {
CallbackReturnValue<ReturnType> crv = new CallbackReturnValue<ReturnType>();
crv.Error = error;
return crv;
}
}
public interface IAsyncFunction<ReturnType>
{
void Execute(CallbackFunction<ReturnType> callback);
}
Here’s a simple example of an asynchronous function implementation:
public class HttpGet : IAsyncFunction<String>
{
private Uri Path;
private CallbackFunction<String> OuterCallback;
private HttpWebRequest Request;
public HttpGet(Uri path)
{
Path = path;
}
public void Execute(CallbackFunction<String> outerCallback)
{
OuterCallback = outerCallback;
try
{
HttpWebRequest Request = (HttpWebRequest)WebRequest.Create(Path);
Request.Method = "GET";
Request.BeginGetRequestStream(InnerCallback,null);
}
catch (Exception ex)
{
OuterCallback(CallbackReturnValue<String>.CreateError(ex));
}
}
public void InnerCallback(IAsyncResult result)
{
try
{
HttpWebResponse response = (HttpWebResponse) Request.EndGetResponse(result);
TextReader reader = new StreamReader(response.GetResponseStream());
OuterCallback(CallbackReturnValue<String>.CreateOk(reader.ReadToEnd()));
} catch(Exception ex) {
OuterCallback(CallbackReturnValue<String>.CreateError(ex));
}
}
}
Asynchronous Functions provide a simple and typesafe way to build asynchronous functions by composing them out of simpler asynchronous functions, and it provides a reasonable way to emulate the usual bubbling of exceptions that allows callers to catch exceptions thrown inside a callee. (Without this kind of intervention, exceptions in the callback functions propagate in the reverse of the usual direction!) Over the next few posts, we’ll talk about how asynchronous execution really works, which is essential for getting good results with Asynchronous Functions.
]]>For instance, suppose that you’re doing a search, and then you’re displaying the result of the search. The most reliable way to do this is to use Pattern Zero, which is, do a single request to the server that retrieves all the information — in that case you don’t need to worry about what happens if, out of 20 HTTP requests, one fails.
Sometimes you can’t redesign the client-server protocol, or you’d like to take advantage of caching, in which case you might do something like this (in psuedo code):
getAListOfResults(new AsyncCallback {
... clearGUI();
foreach(result as item) {
fetchItem(item,new AsyncCallback {
... addItemToGui()
}
}
First we retrieve a list of items, then we retrieve information about each item: this is straightforward, but not always reliable. Even if your application runs in a single thread, as it would in GWT or if you did everything in the UI thread in Silverlight, you can still have race conditions: for instance, results can come back in a random order, and getAListOfResults() can be called more than once by multiple callbacks — that’s really the worst of the problems, because it can cause results to appear more than once in the GUI.
There are a number of solutions to this problem, and a number of non-solutions. A simple solution is to make sure that getAListOfResults() never gets called until the result set has come back. I was able to do that for quite a while last summer, but the application finally reached a level of complexity where it was impossible… or would have required a major redesign of the app. Another is to use pessimistic locking: to not let getAListOfResults() run while result sets are coming back — I think this can be made to work, but if you’re not careful, your app can display stale data or permanently lock up.
Fortunately there’s a pattern to retrieve result sets using optimistic locking that displays fresh data and can’t fail catastrophically
class Whatever {
int transactionId=0;
public updateGUI() {
getAListOfResults(new AsyncCallback {
transactionId++;
final int currentTransactionId=transactionId;
... clearGUI();
foreach(result as item) {
fetchItem(item,new AsyncCallback {
if (transactionId != currentTransactionId)
return
... addItemToGui()
}
}
}
The gist of this is that each result set is assigned a unique transaction id — once the list of items comes back, we clear the GUI, then we ignore fetchItem() callbacks from prior transaction id’s. In a multi-threaded environment, you’ll need to take care that transactionId’s are generated atomically.
Let’s think about how this algorithm holds up in the face of failure: suppose one of the fetchItem() calls fails to return. Perhaps the callback is going to come back with a failure code, but you never know. (It certainly doesn’t in some off-brand browsers with GWT) A pessimistic locking scheme would require some way of knowing when the request is done — it would have to count all the fetchItem() calls that return… If one doesn’t come back, the application could be locked up forever. You could try to fight this by setting a timeout, but getting correct behavior in every strange case could be a lot of work.
The code above might not always do the correct thing, but it always does something sane. If one of the fetchItem() call fails, the item will fail to appear in the list. If the failure is a transient failure, you could say this is a fault of the algorithm: this could be patched over by retrying the failed request. If, on the other hand, the failure is the fault of the server (say the fetchItem() call crashes with a particular argument) this algorithm keeps the client app available.
Note that another detail is missing from this code sample: fetchItem() callbacks can come back in a random order, so that the order that items appear in the GUI is not guaranteed. In some cases you might not care. If you do care, you can associate a sequenceNumber with each fetchItem() request (for instance, using a closure as we do with the currentTransactionId) and then use the sequenceNumber to place each item in the right place in the GUI.
The Optimistic Locking pattern is a simple and provably reliable solution to the problem of retrieving detailed information about items in a result set — in particular, it’s immune to catastrophic failures that can befall pessimistic locking schemes. Many people have proposed solutions to this problem that work sometimes, but not always: you don’t want to waste your time chasing Heisenbugs… Start with reliable patterns and build from there.
