![[Generation Five]](/q/wp-content/themes/mach-go/images/GenerationFive.png)
![[Reliable And Maintainable Software For The Next Generation]](/q/wp-content/themes/mach-go/images/ReliableAndMaintainableSoftwareForTheNextGeneration.png)


How Asynchronous Execution Works in RIAs
CORRECTION: The threading model in Silverlight has changed as of Silverlight 2 Beta 2. It is now possible to initiate asynchronous communication from any thread, however, asynchronous callbacks now run in “new” threads that come from a thread pool. The issues in this article still apply, with two additions: (1) the possibility of race conditions and deadlocks between asynchronous callback threads and (2) all updates to user interface components must be done from the user interface thread. (Fortunately, it’s easy to get back to the UI thread.) Subscribe to our RSS Feed to keep informed of breaking developments in Silverlight development.
There’s a lot of confusion about how asynchronous communication works in RIA’s such as Silverlight, GWT and Javascript. When I start talking about the problems of concurrency control, many people tell me that there aren’t any concurrency problems since everything runs in a single thread. [1]
It’s important to understand the basics of what is going on when you’re writing asynchronous code, so I’ve put together a simple example to show how execution works in RIA’s and how race conditions are possible. This example applies to Javascript, Silverlight, GWT and Flex, as well as a number of other environments based on Javascript. This example doesn’t represent best practices, but rather what can happen when you’re not using a proactive strategy that eliminates concurrency problems:
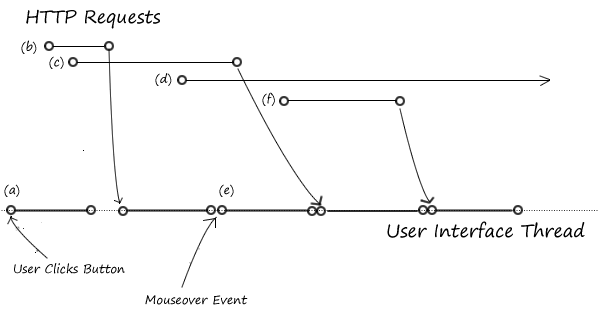
In the diagram above, execution starts when the user pushes a button (a). This starts the user interface thread by invoking an onClick handler. The user interface thread starts two XmlHttpRequests, (b) and (c). The event handler eventually returns, so execution stops in the user interface thread.
In the meantime, the browser still has two XmlHttpRequests running. Callbacks from http requests, timers and user interfaces go into a queue — they get executed right away if the user interface thread is doing nothing, but get delayed if the user interface thread is active.
Http request (b) completes first, causing the http callback for request (b) to start. Had something been a little different with the web browser, web server or network, request (c) could have returned first, causing the callback for request (c) to start. If the result of the program depends on the order that the callbacks for (b) and (c) run, we have a race condition. The callback for http request (b) starts a new http request (d), which runs for a long time.
In the meantime, the user is moving the mouse and triggers a mouseover event while the request (b) callback is running. Right after the request (b) callback completes, the web browser starts the UI thread, which causes a mouseover event handler (e) to run. Note that the user can trigger user interface events while XmlHttpRequests are running, causing event handlers to run in an unpredictable order: if this causes your program to malfunction, your program has a bug.
While the event handler (e) is running, request (c) completes: like the mouseover event, this event is queued and runs once event handler (e) completes. Before (e) completes, it starts a new http request (f). The browser looks into the event queue when (e) completes, and starts the callback for (c). Http request (f) completes while callback (c) is running, gets queued, and runs after (c) is running.
At the end of this example, the callback for (f) completes, causing the UI thread to stop. The http request (c) is still in flight — it completes in the future, somewhere off the end of the page.
This example did not include any timers, or any mechanism of deferred execution such as DeferredCommand in GWT or Dispatcher.Invoke() in Silverlight. This is but another mechanism to add callback references to the event queue.
As you can see, there’s a lot of room for mischief: http requests can return in an arbitrary order and users can initiate events at arbitrary times. The order that things happen in can depend on the browser, it’s settings, on the behavior of the server, and everything in between. Some users might use the application in a way that avoids certain problems (they’ll think it’s wonderful) and others might consistently or occasionally trigger an event that causes catastrophe. These kind of bugs can be highly difficult to reproduce and repair.
Asynchronous RIAs have problems with race conditions that are similar to threaded applications, but not exactly the same. Today’s languages and platforms have excellent and well documented mechanisms for dealing with threads, but today’s RIAs do not have mature mechanisms for dealing with concurrency. Over time we’ll see libraries and frameworks that help, but asynchronous safety isn’t something that can be applied like deodorant: it involves non local interactions between distant parts of the program. The simplest applications can dodge the bullet, but applications beyond a certain level of complexity require an understanding of asynchronous execution and the consistent use of patterns that avoid trouble.
[1] Although it is possible to create new threads in Silverlight, all communication and user interface access must be done from the user interface thread — many Silverlight applications are single-threaded, and adding multiple threads complicates the issue.
Paul Houle on May 2nd 2008 in AJAX, Asynchronous Communications, Dot Net, GWT, Java, Silverlight