I program in PHP a lot, but I’ve avoided using autoloaders, except when I’ve been working in frameworks, such as symfony, that include an autoloader. Last month I started working on a system that’s designed to be part of a software product line: many scripts, for instance, are going to need to deserialize objects that didn’t exist when the script was written: autoloading went from a convenience to a necessity.
The majority of autoloaders use a fixed mapping between class names and PHP file names. Although that’s fine if you obey a strict “one class, one file” policy, that’s a policy that I don’t follow 100% of the time. An additional problem is that today’s PHP applications often reuse code from multiple frameworks and libraries that use different naming conventions: often applications end up registering multiple autoloaders. I was looking for an autoloader that “just works” with a minimum of convention and configuration — and I found that in a recent autoloader developed by A.J. Brown.
After presenting the way that I integrated Brown’s autoloader into my in-house frameowrk, this article considering the growing controversy over require(), require_once() and autoloading performance: to make a long story short, people are experiencing very different results in different environments, and the growing popularity of autoloading is going to lead to changes in PHP and the ecosystem around it.
History: PHP 4 And The Bad Old Days
In the past, PHP programmers have included class definitions in their programs with the following four built-in functions:
- include
- require
- include_once
- require_once
The difference between the include and require functions is that execution of a program will continue if a call to include fails and will result in an error if a call to require fails. require_ and require_once are reccomended for general use, since you’d probably rather have an application fail if libraries are missing rather than barrel on with unpredictable results. (Particularly if the missing library is responsible for authentication.)
If you write
01 require "filename.php";
PHP will scan the PHP include_path for a directory that contains a file called “filename.php”; it then executes the content of “filename.php” right where the function is called. You can do some pretty funky things this way, for instance, you can write
02 for (int i=0;i<10;$i++) {
03 require "template-$i.php";
04 }
to cause the sequential execution of a namset of PHP files named “template-0.php” through “template-9.php.” A required file has access to local variables in the scope that require is called, so require is particularly useful for web templating and situations that require dynamic dispatch (when you compute the filename.) A cool, but slightly obscure feature, is that an included file can return a value. If an source file, say “compute-value.php” uses the return statement,
05 return $some_value;
the value $some_value will be return by require:
06 $value=require "compute-value.php";
These features can be used to create an MVC-like framework where views and controllers are implemented as source files rather than objects.
require isn’t so appropriate, however, when you’re requiring a file that contains class definitions. Imagine we have a hiearchy of classes like Entity -> Picture -> PictureOfACar,PictureOfAnAnimal. It’s quite tempting for PictureofACar.php and PictureofAnAnimal.php to both
07 require "Picture.php";
this works fine if an application only uses PictureOfACar.php and requires it once by writing
08 require "PictureOfACar.php";
It fails, however, if an application requires both PictureOfACar and PictureOfAnAnimal since PHP only allows a class to be defined once.
require_once neatly solves this problem by keeping a list of files that have been required and doing nothing if a file has already been required. You can use require_once in any place where you’d like to guarantee that a class is available, and expect that things “just work”
__autoload
Well, things don’t always “just work”. Although large PHP applications can be maintained with require_once, it becomes an increasing burden to keep track of require files as applications get larger. require_once also breaks down once frameworks start to dynamically instantiate classes that are specified in configuration files. The developers of PHP found a creative solution in the __autoload function, a “magic” function that you can define. __autoload($class_name) gets called whenever a PHP references an undefined class. A very simple __autoload implementation can work well: for instance, the PHP manual page for __autoload has the following code snippet:
09 function _autoload($class_name) {
10 require_once $class_name . '.php';
11 }
If you write
12 $instance=new MyUndefinedClass();
this autoloader will search the PHP include path for “MyUndefinedClass.php.” (A real autoloader should be a little more complex than this: the above autoloader could be persuaded to load from an unsafe filename if user input is used to instantiate a class dynamically, i.e.
13 $instance=new $derived_class_name();
Static autoloading and autoloader proliferation
Unlike Java, PHP does not have a standard to relate source file names with class names. Some PHP developers imitate the Java convention to define one file per class and name their files something like
ClassName.php, or
ClassName.class.php
A typical project that uses code from several sources will probably have sections that are written with different conventions For instance, the Zend framework turns “_” into “/” when it creates paths, so the definition of “Zend_Loader” would be found underneath “Zend/Loader.php.”
A single autoloader could try a few different conventions, but the answer that’s become most widespread is for each PHP framework or library to contain it’s own autoloader. PHP 5.2 introduced the spl_register_autoload() function to replace __autoload(). spl_register_autoload() allows us to register multiple autoloaders, instead of just one. This is ugly, but it works.
One Class Per File?
A final critique of static autoloading is that it’s not universally held that “one class one file” is the best practice for PHP development. One of the advantages of OO scripting languages such as PHP and Python is that you can start with a simple procedural script and gradually evolve it into an OO program by gradual refactoring. A convention that requires to developers to create a new file for each class tends to:
- Discourage developers from creating classes
- Discourage developers from renaming classes
- Discourage developers from deleting classes
These can cumulatively lead programmers to make decisions based on what’s convenient to do with their development tools, not based on what’s good for the software in the long term. These considerations need to be balanced against:
- The ease of finding classes when they are organized “once class per file”,
- The difficulty of navigating huge source code files that contain a large number of classes, and
- Toolset simplification and support.
The last of these is particularly important when we compare PHP with Java. Since the Java compiler enforces a particular convention, that convention is supported by Java IDE’s. The problems that I mention above are greatly reduced if you use an IDE such as Eclipse, which is smart enough to rename files when you rename a class. PHP developers don’t benefit from IDEs that are so advanced — it’s much more difficult for IDE’s to understand a dynamic language. Java also supports inner classes, which allow captive classes (that are only accessed from within an enclosing class) to be defined inside the same file as the enclosing class. Forcing captive classes to be defined in separate files can cause a bewildering number of files to appear, which, in turn, can discourage developers from using captive classes — and that can lead to big mistakes.
Dynamic Autoloading
A. J. Brown has developed an autoloader that uses PHP’s tokenizer() to search a directory full of PHP files, search the files for classes, and create a mapping from class names to php source files. tokenizer() is a remarkable metaprogramming facility that makes it easy to write PHP programs that interpret PHP source. In 298 lines of code, Brown defines three classes. To make his autoloader fit into my in-house framework, I copied his classes into two files:
- lib/nails_core/autoloader.php: ClassFileMap, ClassFileMapAutoloader
- lib/nails_core/autoloader_initialize.php: ClassFileMapFactory
I’m concerned about the overhead of repeatedly traversing PHP library directories and parsing the files, so I run the following program to create the ClassFileMap, serialize it, and store it in a file:
bin/create_class_map.php:
14 <?php
15
16 $SUPRESS_AUTOLOAD=true;
17 require_once(dirname(__FILE__)."/../_config.php");
18 require_once "nails_core/autoloader_initialize.php";
19 $lib_class_map = ClassFileMapFactory::generate($APP_BASE."/lib");
20 $_autoloader = new ClassFileMapAutoloader();
21 $_autoloader->addClassFileMap($lib_class_map);
22 $data=serialize($_autoloader);
23 file_put_contents("$APP_BASE/var/classmap.ser",$data);
Note that I’m serializing the ClassFileMapAutoloader rather than the ClassFileMap, since I’d like to have the option of specifying more than one search directory. To follow the “convention over configuration” philosophy, a future version will probable traverse all of the directories in the php_include_path.
All of the PHP pages, controllers and command-line scripts in my framework have the line
24 require_once(dirname(__FILE__)."/../_config.php");
which includes a file that is responsible for configuring the application and the PHP environment. I added a bit of code to the _config.php to support the autoloader:
_config.php:
25 <?php
26 $APP_BASE = "/where/app/is/in/the/filesystem";
...
27 if (!isset($SUPPRESS_AUTOLOADER)) {
28 require_once "nails_core/autoloader.php";
29 $_autoloader=unserialize(file_get_contents($APP_BASE."/var/classmap.ser"));
30 $_autoloader->registerAutoload();
31 };
Pretty simple.
Autoloading And Performance
Although there’s plenty of controversy about issues of software maintainability, I’ve learned the hard way that it’s hard to make blanket statements about performance — results can differ based on your workload and the exact environment you’re working in. Although Brown makes the statement that “We do add a slight overhead to the application,” many programmers are discovering that autoloading improves performance over require_once:
Zend_Loader Performance Analysis
Autoloading Classes To Reduce CPU Usage
There seem to be two issues here: first of all, most systems that use require_once are going to err on the side of including more files than they need rather than fewer — it’s better to make a system slower and bloated than to make it incorrect. A system that uses autoloading will spend less time loading classes, and, just as important, less memory storing them. Second, PHP programmers appear to be experience variable results with require() and require_once():
Wikia Developer Finds require_once() Slower Than require()
Another Developer Finds Little Difference
Yet Another Developer Finds It Depends On His Cache Configuration
Rumor has it, PHP 5.3 improves require_once() performance
One major issues is that require_once() calls the realpath() C function, which in turn calls the lstat() system call. The cost of system calls can vary quite radically on different operating systems and even different filesystems. The use of an opcode cache such as XCache or APC can also change the situation.
It appears that current opcode caches (as of Jan 2008) don’t efficiently support autoloading:
Mike Willbanks Experience Slowdown With Zend_Loader
APC Developer States That Autoloading is Incompatible With Cacheing
Rambling Discussion of the state of autoloading with XCache
the issue is that they don’t, at compile time, know what files are going be required by the application. Opcode caches also reduce the overhead of loading superfluous classes, so they don’t get the benefits experienced with plain PHP.
It all reminds me of the situation with synchronized in Java. In early implementations of Java, synchronized method calls had an execution time nearly ten times longer than ordinary message calls. Many developers designed systems (such as the Swing windowing toolkit) around this performance problem. Modern VM’s have greatly accelerated the synchronization mechanism and can often optimize superfluous synchronizations away — so the performance advice of a decade ago is bunk.
Language such as Java are able to treat individual classes as compilation units: and I’d imagine that, with certain restrictions, a PHP bytecode cache should be able to do just that. This may involve some changes in the implementation of PHP.
Conclusion
Autoloading is an increasingly popular practice among PHP developers. Autoloading improves development productivity in two ways:
- It frees developers from thinking about loading the source files needed by an application, and
- It enables dynamic dispatch, situations where a script doesn’t know about all the classes it will interact with when it’s written
Since PHP allows developers to create their own autoloaders, a number of autoloaders exist. Many frameworks, such as the Zend Framework, symfony, and CodeIgniter, come with autoloaders — as a result, some PHP applications might contain more than one autoloader. Most autoloaders require that classes be stored in files with specific names, but Brown’s autoloader can scan directory trees to automatically locate PHP classes and map them to filenames. Eliminating the need for both convention and configuration, I think it’s a significant advance: in many cases I think it could replace the proliferation of autoloaders that we’re seeing today.
You’ll hear very different stories about the performance of autoload, require_once() and other class loading mechanisms from different people. The precise workload, operating system, PHP version, and the use of an opcode cache appear to be important factors. Widespread use of autoloading will probably result in optimization of autoloading throughout the PHP ecosystem.
]]>This article is a follow up to “Don’t Catch Exceptions“, which advocates that exceptions should (in general) be passed up to a “unit of work”, that is, a fairly coarse-grained activity which can reasonably be failed, retried or ignored. A unit of work could be:
- an entire program, for a command-line script,
- a single web request in a web application,
- the delivery of an e-mail message
- the handling of a single input record in a batch loading application,
- rendering a single frame in a media player or a video game, or
- an event handler in a GUI program
The code around the unit of work may look something like
[01] try {
[02] DoUnitOfWork()
[03] } catch(Exception e) {
[04] ... examine exception and decide what to do ...
[05] }
For the most part, the code inside DoUnitOfWork() and the functions it calls tries to throw exceptions upward rather than catch them.
To handle errors correctly, you need to answer a few questions, such as
- Was this error caused by a corrupted application state?
- Did this error cause the application state to be corrupted?
- Was this error caused by invalid input?
- What do we tell the user, the developers and the system administrator?
- Could this operation succeed if it was retried?
- Is there something else we could do?
Although it’s good to depend on existing exception hierarchies (at least you won’t introduce new problems), the way that exceptions are defined and thrown inside the work unit should help the code on line [04] make a decision about what to do — such practices are the subject of a future article, which subscribers to our RSS feed will be the first to read.
The cause and effect of errors
There are a certain range of error conditions that are predictable, where it’s possible to detect the error and implement the correct response. As an application becomes more complex, the number of possible errors explodes, and it becomes impossible or unacceptably expensive to implement explicit handling of every condition.
What do do about unanticipated errors is a controversial topic. Two extreme positions are: (i) an unexpected error could be a sign that the application is corrupted, so that the application should be shut down, and (ii) systems should bend but not break: we should be optimistic and hope for the best. Ultimately, there’s a contradiction between integrity and availability, and different systems make different choices. The ecosystem around Microsoft Windows, where people predominantly develop desktop applications, is inclined to give up the ghost when things go wrong — better to show a “blue screen of death” than to let the unpredictable happen. In the Unix ecosystem, more centered around server applications and custom scripts, the tendency is to soldier on in the face of adversity.
What’s at stake?
Desktop applications tend to fail when unexpected errors happen: users learn to save frequently. Some of the best applications, such as GNU emacs and Microsoft Word, keep a running log of changes to minimize work lost to application and system crashes. Users accept the situation.
On the other hand, it’s unreasonable for a server application that serves hundreds or millions of users to shut down on account of a cosmic ray. Embedded systems, in particular, function in a world where failure is frequent and the effects must be minimized. As we’ll see later, it would be a real bummer if the Engine Control Unit in your car left you stranded home because your oxygen sensor quit working.
The following diagram illustrates the environment of a work unit in a typical application: (although this application accesses network resources, we’re not thinking of it as a distributed application. We’re responsible for the correct behavior of the application running in a single address space, not about the correct behavior of a process swarm.)

The Input to the work unit is a potential source of trouble. The input could be invalid, or it could trigger a bug in the work unit or elsewhere in the system (the “system” encompasses everything in the diagram) Even if the input is valid, it could contain a reference to a corrupted resource, elsewhere in the system. A corrupted resource could be a damaged data structure (such as a colored box in a database), or an otherwise malfunctioning part of the system (a crashed server or router on the network.)
Data structures in the work unit itself are the least problematic, for purposes of error handling, because they don’t outlive the work unit and don’t have any impact on future work units.
Static application data, on the other hand, persists after the work unit ends, and this has two possible consequences:
- The current work unit can fail because a previous work unit caused a resource to be corrupted, and
- The current work unit can corrupt a resource, causing a future work unit to fail
Osterman’s argument that applications should crash on errors is based on this reality: an unanticipated failure is a sign that the application is in an unknown (and possibly bad) state, and can’t be trusted to be reliable in the future. Stopping the application and restarting it clears out the static state, eliminating resource corruption.
Rebooting the application, however, might not free up corrupted resources inside the operating system. Both desktop and server applications suffer from operating system errors from time to time, and often can get immediate relief by rebooting the whole computer.
The “reboot” strategy runs out of steam when we cross the line from in-RAM state to persistent state, state that’s stored on disks, or stored elsewhere on the network. Once resources in the persistent world are corrupted, they need to be (i) lived with, or repaired by (ii) manual or (iii) automatic action.
In either world, a corrupted resource can have either a narrow (blue) or wide (orange) effect on the application. For instance, the user account record of an individual user could be damaged, which prevents that user from logging in. That’s bad, but it would hardly be catastrophic for a system that has 100,000 users. It’s best to ‘ignore’ this error, because a system-wide ‘abort’ would deny service to 99,999 other users; the problem can be corrected when the user complains, or when the problem is otherwise detected by the system administrator.
If, on the other hand, the cryptographic signing key that controls the authentication process were lost, nobody would be able to log in: that’s quite a problem. It’s kind of the problem that will be noticed, however, so aborting at the work unit level (authenticated request) is enough to protect the integrity of the system while the administrators repair the problem.
Problems can happen at an intermediate scope as well. For instance, if the system has damage to a message file for Italian users, people who use the system in the Italian language could be locked out. If Italian speakers are 10% of the users, it’s best to keep the system running for others while you correct the problem.
Repair
There are several tools for dealing with corruption in persistent data stores. In a one-of-a-kind business system, a DBA may need to intervene occasionally to repair corruption. More common events can be handled by running scripts which detect and repair corruption, much like the fsck command in Unix or the chkdsk command in Windows. Corruption in the metadata of a filesystem can, potentially, cause a sequence of events which leads to massive data loss, so UNIX systems have historically run the fsck command on filesystems whenever the filesystem is in a questionable state (such as after a system crash or power failure.) The time do do an fsck has become an increasing burden as disks have gotten larger, so modern UNIX systems use journaling filesystems that protect filesystem metadata with transactional semantics.
Release and Rollback
One role of an exception handler for a unit of work is to take steps to prevent corruption. This involves the release of resources, putting data in a safe state, and, when possible, the rollback of transactions.
Although many kinds of persistent store support transactions, and many in-memory data structures can support transactions, the most common transactional store that people use is the relational database. Although transactions don’t protect the database from all programming errors, they can ensure that neither expected or unexpected exceptions will cause partially-completed work to remain in the database.
A classic example in pseudo code is the following:
[06] function TransferMoney(fromAccount,toAccount,amount) {
[07] try {
[08] BeginTransaction();
[09] ChangeBalance(toAccount,amount);
[10] ... something throws exception here ...
[11] ChangeBalance(fromAccount,-amount);
[12] CommitTransaction();
[13] } catch(Exception e) {
[14] RollbackTransaction();
[15] }
[16] }
In this (simplified) example, we’re transferring money from one bank account to another. Potentially an exception thrown at line [05] could be serious, since it would cause money to appear in toAccount without it being removed from fromAccount. It’s bad enough if this happens by accident, but a clever cracker who finds a way to cause an exception at line [05] has discovered a way to steal money from the bank.
Fortunately we’re doing this financial transaction inside a database transaction. Everything done after BeginTransaction() is provisional: it doesn’t actually appear in the database until CommitTransaction() is called. When an exception happens, we call RollbackTransaction(), which makes it as if the first ChangeBalance() had never been called.
As mentioned in the “Don’t Catch Exceptions” article, it often makes sense to do release, rollback and repairing operations in a finally clause rather than the unit-of-work catch clause because it lets an individual subsystem take care of itself — this promotes encapsulation. However, in applications that use databases transactionally, it often makes sense to push transaction management out the the work unit.
Why? Complex database operations are often composed out of simpler database operations that, themselves, should be done transactionally. To take an example, imagine that somebody is opening a new account and funding it from an existing account:
[17] function OpenAndFundNewAccount(accountInformation,oldAccount,amount) {
[18] if (amount<MinimumAmount) {
[19] throw new InvalidInputException(
[20] "Attempted To Create Account With Balance Below Minimum"
[21] );
[22] }
[23] newAccount=CreateNewAccountRecords(accountInformation);
[24] TransferMoney(oldAccount,newAccount,amount);|
[25] }
It’s important that the TransferMoney operation be done transactionally, but it’s also important that the whole OpenAndFundNewAccount operation be done transactionally too, because we don’t want an account in the system to start with a zero balance.
A straightforward answer to this problem is to always do banking operations inside a unit of work, and to begin, commit and roll back transactions at the work unit level:
[26] AtmOutput ProcessAtmRequest(AtmInput in) {
[27] try {
[28] BeginTransaction();
[29] BankingOperation op=AtmInput.ParseOperation();
[30] var out=op.Execute();
[31] var atmOut=AtmOutput.Encode(out);
[32] CommitTransaction();
[33] return atmOut;
[34] }
[35] catch(Exception e) {
[36] RollbackTransaction();
[37] ... Complete Error Handling ...
[38] }
In this case, there might be a large number of functions that are used to manipulate the database internally, but these are only accessable to customers and bank tellers through a limited set of BankingOperations that are always executed in a transaction.
Notification
There are several parties that could be notified when something goes wrong with an application, most commonly:
- the end user,
- the system administrator, and
- the developers.
Sometimes, as in the case of a public-facing web application, #2 and #3 may overlap. In desktop applications, #2 might not exist.
Let’s consider the end user first. The end user really needs to know (i) that something went wrong, and (ii) what they can do about it. Often errors are caused by user input: hopefully these errors are expected, so the system can tell the user specifically what went wrong: for instance,
[39] try {
[40] ... process form information ...
[41]
[42] if (!IsWellFormedSSN(ssn))
[43] throw new InvalidInputException("You must supply a valid social security number");
[44]
[45] ... process form some more ...
[46] } catch(InvalidInputException e) {
[47] DisplayError(e.Message);
[48] }
other times, errors happen that are unexpected. Consider a common (and bad) practice that we see in database applications: programs that write queries without correctly escaping strings:
[49] dbConn.Execute("
[50] INSERT INTO people (first_name,last_name)
[51] VALUES ('"+firstName+"','+lastName+"');
[52] ");
this code is straightforward, but dangerous, because a single quote in the firstName or lastName variable ends the string literal in the VALUES clause, and enables an SQL injection attack. (I’d hope that you know better than than to do this, but large projects worked on by large teams inevitably have problems of this order.) This code might even hold up well in testing, failing only in production when a person registers with
[53] lastName="O'Reilly";
Now, the dbConn is going to throw something like a SqlException with the following message:
[54] SqlException.Message="Invalid SQL Statement:
[55] INSERT INTO people (first_name,last_name)
[56] VALUES ('Baba','O'Reilly');"
we could show that message to the end user, but that message is worthless to most people. Worse than that, it’s harmful if the end user is a cracker who could take advantage of the error — it tells them the name of the affected table, the names of the columns, and the exact SQL code that they can inject something into. You might be better off showing users something like:

and telling them that they’ve experienced an “Internal Server Error.” Even so, the discovery that a single quote can cause an “Internal Server Error” can be enough for a good cracker to sniff out the fault and develop an attack in the blind.. What can we do? Warn the system administrators. The error handling system for a server application should log exceptions, stack trace and all. It doesn’t matter if you use the UNIX syslog mechanism, the logging service in Windows NT, or something that’s built into your server, like Apache’s error_log. Although logging systems are built into both Java and .Net, many developers find that Log4J and Log4N are especially effective.
There really are two ways to use logs:
- Detailed logging information is useful for debugging problems after the fact. For instance, if a user reports a problem, you can look in the logs to understand the origin of the problem, making it easy to debug problems that occur rarely: this can save hours of time trying to understand the exact problem a user is experiencing.
- A second approach to logs is proactive: to regularly look a logs to detect problems before they get reported. In the example above, the SqlException would probably first be thrown by an innocent person who has an apostrophe in his or her name — if the error was detected that day and quickly fixed, a potential security hole could be fixed long before it would be exploited. Organizaitons that investigate all exceptions thrown by production web applications run the most secure and reliable applications.
In the last decade it’s become quite common for desktop applications to send stack traces back to the developers after a crash: usually they pop up a dialog box that asks for permission first. Although developers of desktop applications can’t be as proactive as maintainers of server applications, this is a useful tool for discovering errors that escape testing, and to discover how commonly they occur in the field.
Retry I: Do it again!
Some errors are transient: that is, if you try to do the same operation later, the operation may succeed. Here are a few common cases:
- An attempt to write to a DVD-R could fail because the disk is missing from the drive
- A database transaction could fail when you commit it because of a conflict with another transaction: an attempt to do the transaction again could succeed
- An attempt to deliver a mail message could fail because of problems with the network or destination mail server
- A web crawler that crawls thousands (or millions) of sites will find that many of them are down at any given time: it needs to deal with this reasonably, rather than drop your site from it’s index because it happened to be down for a few hours
Transient errors are commonly associated with the internet and with remote servers; errors are frequent because of the complexity of the internet, but they’re transitory because problems are repaired by both automatic and human intervention. For instance, if a hardware failure causes a remote web or email server to go down, it’s likely that somebody is going to notice the problem and fix it in a few hours or days.
One strategy for dealing with transient errors is to punt it back to the user: in a case like this, we display an error message that tells the user that the problem might clear up if they retry the operation. This is implicit in how web browsers work: sometimes you try to visit a web page, you get an error message, then you hit reload and it’s all OK. This strategy is particularly effective when the user could be aware that there’s a problem with their internet connection and could do something about it: for instance, they might discover that they’ve moved their laptop out of Wi-Fi range, or that the DSL connection at their house has gone down for the weekend.
SMTP, the internet protocol for email, is one of the best examples of automated retry. Compliant e-mail servers store outgoing mail in a queue: if an attempt to send mail to a destination server fails, mail will stay in the queue for several days before reporting failure to the user. Section 4.5.4 of RFC 2821 states:
The sender MUST delay retrying a particular destination after one attempt has failed. In general, the retry interval SHOULD be at least 30 minutes; however, more sophisticated and variable strategies will be beneficial when the SMTP client can determine the reason for non-delivery. Retries continue until the message is transmitted or the sender gives up; the give-up time generally needs to be at least 4-5 days. The parameters to the retry algorithm MUST be configurable. A client SHOULD keep a list of hosts it cannot reach and corresponding connection timeouts, rather than just retrying queued mail items. Experience suggests that failures are typically transient (the target system or its connection has crashed), favoring a policy of two connection attempts in the first hour the message is in the queue, and then backing off to one every two or three hours.
Practical mail servers use fsync() and other mechanisms to implement transactional semantics on the queue: the needs of reliability make it expensive to run an SMTP-compliant server, so e-mail spammers often use non-compliant servers that don’t correctly retry (if they’re going to send you 20 copies of the message anyway, who cares if only 15 get through?) Greylisting is a highly effective filtering strategy that tests the compliance of SMTP senders by forcing a retry.
Retry II: If first you don’t succeed…
An alternate form of retry is to try something different. For instance, many programs in the UNIX environment will look in many different places for a configuration file: if the file isn’t in the first place tried, it will try the second place and so forth.
The online e-print server at arXiv.org has a system called AutoTex which automatically converts documents written in several dialects of TeX and LaTeX into Postscript and PDF files. AutoTex unpacks the files in a submission into a directory and uses chroot to run the document processing tools in a protected sandbox. It tries about of ten different configurations until it finds one that successfully compiles the document.
In embedded applications, where availability is important, it’s common to fall back to a “safe mode” when normal operation is impossible. The Engine Control Unit in a modern car is a good example:

Since the 1970′s, regulations in the United States have reduced emissions of hydrocarbons and nitrogen oxides from passenger automobiles by more than a hundred fold. The technology has many aspects, but the core of the system in an Engine Control Unit that uses a collection of sensors to monitor the state of the engine and uses this information to adjust engine parameters (such as the quantity of fuel injected) to balance performance and fuel economy with environmental compliance.
As the condition of the engine, driving conditions and composition of fuel change over the time, the ECU normally operates in a “closed-loop” mode that continually optimizes performance. When part of the system fails (for instance, the oxygen sensor) the ECU switches to an “open-loop” mode. Rather than leaving you stranded, it lights the “check engine” indicator and operates the engine with conservative assumptions that will get you home and to a repair shop.
Ignore?
One strength of exceptions, compared to the older return-value method of error handling is that the default behavior of an exception is to abort, not to ignore. In general, that’s good, but there are a few cases where “ignore” is the best option. Ignoring an error makes sense when:
- Security is not at stake, and
- there’s no alternative action available, and
- the consequences of an abort are worse than the consequences of avoiding an error
The first rule is important, because crackers will take advantage of system faults to attack a system. Imagine, for instance, a “smart card” chip embedded in a payment card. People have successfully extracted information from smart cards by fault injection: this could be anything from a power dropout to a bright flash of light on an exposed silicon surface. If you’re concerned that a system will be abused, it’s probably best to shut down when abnormal conditions are detected.
On the other hand, some operations are vestigial to an application. Imagine, for instance, a dialog box that pops when an application crashes that offers the user the choice of sending a stack trace to the vendor. If the attempt to send the stack trace fails, it’s best to ignore the failure — there’s no point in subjecting the user to an endless series of dialog boxes.
“Ignoring” often makes sense in the applications that matter the most and those that matter the least.
For instance, media players and video games operate in a hostile environment where disks, the network, sound and controller hardware are uncooperative. The “unit of work” could be the rendering of an individual frame: it’s appropriate for entertainment devices to soldier on despite hardware defects, unplugged game controllers, network dropouts and corrupted inputs, since the consequences of failure are no worse than shutting the system down.
In the opposite case, high-value systems and high-risk should continue functioning no matter what happen. The software for a space probe, for instance, should never give up. Much like an automotive ECU, space probes default to a “safe mode” when contact with the earth is lost: frequently this strategy involves one or more reboots, but the goal is to always regain contact with controllers so that the mission has a chance at success.
Conclusion
It’s most practical to catch exceptions at the boundaries of relatively coarse “units of work.” Although the handling of errors usually involves some amount of rollback (restoring system state) and notification of affected people, the ultimate choices are still what they were in the days of DOS: abort, retry, or ignore.
Correct handling of an error requires some thought about the cause of an error: was it caused by bad input, corrupted application state, or a transient network failure? It’s also important to understand the impact the error has on the application state and to try to reduce it using mechanisms such as database transactions.
“Abort” is a logical choice when an error is likely to have caused corruption of the application state, or if an error was probably caused by a corrupted state. Applications that depend on network communications sometimes must “Retry” operations when they are interrupted by network failures. Another form of “Retry” is to try a different approach to an operation when the first approach fails. Finally, “Ignore” is appropriate when “Retry” isn’t available and the cost of “Abort” is worse than soldiering on.
This article is one of a series on error handling. The next article in this series will describe practices for defining and throwing exceptions that gives exception handlers good information for making decisions. Subscribers to our RSS Feed will be the first to read it.
]]>It’s clear that a lot of programmers are uncomfortable with exceptions [1] [2]; in the feedback of an article I wrote about casting, it seemed that many programmers saw the throwing of a NullReferenceException at a cast to be an incredible catastrophe.
In this article, I’ll share a philosophy that I hope will help programmers overcome the widespread fear of exceptions. It’s motivated by five goals:
- Do no harm
- To write as little error handling code as possible,
- To think about error handling as little as possible
- To handle errors correctly when possible,
- Otherwise errors should be handled sanely
To do that, I
- Use finally to stabilize program state when exceptions are thrown
- Catch and handle exceptions locally when the effects of the error are local and completely understood
- Wrap independent units of work in try-catch blocks to handle errors that have global impact
This isn’t the last word on error handling, but it avoids many of the pitfalls that people fall into with exceptions. By building upon this strategy, I believe it’s possible to develop an effective error handling strategy for most applications: future articles will build on this topic, so keep posted by subscribing to the Generation 5 RSS Feed.
The Tragedy of Checked Exceptions
Java’s done a lot of good, but checked exceptions are probably the worst legacy that Java has left us. Java has influenced Python, PHP, Javascript, C# and many of the popular languages that we use today. Unfortunately, checked exceptions taught Java programmers to catch exceptions prematurely, a habit that Java programmers carried into other languages, and has result in a code base that sets bad examples.
Most exceptions in Java are checked, which means that the compiler will give you an error if you write
[01] public void myMethod() {
[02] throw new ItDidntWorkException()
[03] };
unless you either catch the exception inside myMethod or you replace line [01] with
[04] public void myMethod() throws ItDidntWorkException {
The compiler is also aware of any checked exceptions that are thrown by methods underneath myMethod, and forces you to either catch them inside myMethod or to declare them in the throws clause of myMethod.
I thought that this was a great idea when I started programming Java in 1995. With the hindsight of a decade, we can see that it’s a disaster. The trouble is that every time you call a method that throws an exception, you create an immediate crisis: you break the build. Rather than conciously planning an error handling strategy, programmers do something, anything, to make the compiler shut up. Very often you see people bypass exceptions entirely, like this:
[05] public void someMethod() {
[06] try {
[07] objectA.anotherMethod();
[08] } catch(SubsystemAScrewedUpException ex) { };
[09] }
Often you get this instead:
[10] try {
[11] objectA.anotherMethod();
[12] } catch(SubsystemAScrewedUp ex) {
[13] // something ill-conceived to keep the compiler happy
[14] }
[15] // Meanwhile, the programmer makes a mistake here because
[16] // writing an exception handler broke his concentration
This violates the first principle, to “do no harm.” It’s simple, and often correct, to pass the exception up to the calling function,
[17] public int someMethod() throws SubsystemAScrewedUp {
But, this still breaks the build, because now every function that calls someMethod() needs to do something about the exception. Imagine a program of some complexity that’s maintained by a few programmers, in which method A() calls method B() which calls method C() all the way to method F().
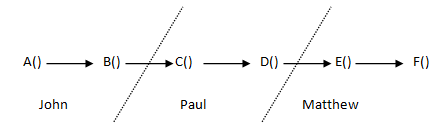
The programmer who works on method F() can change the signature of that method, but he may not have the authority to change the signature of the methods above. Depending on the culture of the shop, he might be able to do it himself, he might talk about it with the other programmers over IM, he might need to get the signatures of three managers, or he might need to wait until the next group meeting. If they keep doing this, however, A() might end up with a signature like
[18] public String A() throws SubsystemAScrewedUp, IOException, SubsystemBScrewedUp, [19] WhateverExceptionVendorZCreatedToWrapANullPointerException, ...
This is getting out of hand, and they realize they can save themselvesa lot of suffering by just writing
[20] public int someMethod() throws Exception {
all the time, which is essentially disabling the checked exception mechanism. Let’s not dismiss the behavior of the compiler out of hand, however, because it’s teaching us an important lesson: error handling is a holistic property of a program: an error handled in method F() can have implications for methods A()…E(). Errors often break the assumption of encapsulation, and require a global strategy that’s applied consistently throughout the code.
PHP, C# and other post-Java languages tend to not support checked exceptions. Unfortunately, checked exception thinking has warped other langages, so you’ll find that catch statements are used neurotically everywhere.
Exception To The Rule: Handling Exceptions Locally
Sometimes you can anticipate an exception, and know what exact action to take. Consider the case of a compiler, or a program that processes a web form, which might find more than one error in user input. Imagine something like (in C#):
[21] List<string> errors=new List<string>();
[22] uint quantity=0;
[23] ... other data fields ...
[24]
[25] try {
[26] quantity=UInt32.Parse(Params["Quantity"]);
[27] } catch(Exception ex) {
[28] errors.Add("You must enter a valid quantity");
[29] }
[30]
[31] ... other parsers/validators ...
[32]
[33] if (errors.Empty()) {
[34] ... update database, display success page ...
[35] } else {
[36] ... redraw form with error messages ...
[37] }
Here it makes sense to catch the exception locally, because the exceptions that can happen on line [22] are completely handled, and don’t have an effect on other parts of the application. The one complaint you might make is that I should be catching something more specific than Exception. Well, that would bulk the code up considerably and violate the DRY (don’t repeat yourself) principle: UInt32.Parse can throw three different exceptions: ArgumentNullException, FormatException, and OverflowException. On paper, the process of looking up the “Quantity” key in Params could throw an ArgumentNullException or a KeyNotFoundException.
I don’t think either ArgumentNullException can really happen, and I think the KeyNotFoundException would only occur in development, or if somebody was trying to submit the HTML form with an unauthorized program. Probably the best thing to do in either case would be to abort the script with a 500 error and log the details, but the error handling on line [24] is sane in that it prevents corruption of the database.
The handling of FormatException and OverflowException, in the other case, is fully correct. The user gets an error message that tells them what they need to do to fix the situation.
This example demonstrates a bit of why error handling is so difficult and why the perfect can be the enemy of the good: the real cause of an IOException could be a microscopic scratch on the surface of a hard drive, and operating system error, or the fact that somebody spilled a coke on a router in Detroit — diagnosing the problem and offering the right solution is an insoluble problem.
Fixing it up with finally
The first exception handling construct that should be on your fingertips is finally, not catch. Unfortunately, finally is a bit obscure: the pattern in most languages is
[38] try {
[39] ... do something that might throw an exception ...
[40] } finally {
[41] ... clean up ...
[42] }
The code in the finally clause get runs whether or not an exception is thrown in the try block. Finally is a great place to release resources, roll back transactions, and otherwise protect the state of the application by enforcing invariants. Let’s think back to the chain of methods A() through F(): with finally, the maintainer of B() can implement a local solution to a global problem that starts in F(): no matter what goes wrong downstream, B() can repair invariants and repair the damage. For instance, if B()’s job is to write something into a transactional data store, B() can do something like:
[43] Transaction tx=new Transaction();
[44] try {
[45] ...
[46] C();
[47] ...
[48] tx.Commit();
[49] } finally {
[50] if (tx.Open)
[51] tx.Rollback();
[52] }
This lets the maintainer of B() act defensively, and offer the guarantee that the persistent data store won’t get corrupted because of an exception that was thrown in the try block. Because B() isn’t catching the exception, it can do this without depriving upstream methods, such as A() from doing the same.
C# gets extra points because it has syntactic sugar that makes a simple case simple: The using directive accepts an IDisposable as an argument and wraps the block after it with a finally clause that calls the Dispose() method of the IDisposable. ASP.NET applications can fail catastrophically if you don’t Dispose() database connections and result sets, so
[53] using (var reader=sqlCommand.ExecuteReader()) {
[54] ... scroll through result set ...
[55] }
is a widespread and effective pattern.
PHP loses points because it doesn’t support finally. Granted, finally isn’t as important in PHP, because all resources are released when a PHP script ends. The absense of finally, however, encourages PHP programmers to overuse catch, which perpetuates exception phobia. The PHP developers are adding great features to PHP 5.3, such as late static binding, so we can hope that they’ll change their mind and bring us a finally clause.
Where should you catch exceptions?
At high levels of your code, you should wrap units of work in a try-catch block. A unit of work is something that makes sense to either give up on or retry. Let’s work out a few simple examples:
Scripty Command line program: This program is going to be used predominantly by the person who wrote it and close associates, so it’s acceptable for the program to print a stack trace if it fails. The “unit of work” is the whole program.
Command line script that processes a million records: It’s likely that some records are corrupted or may trigger bugs in the program. Here it’s reasonable for the “unit of work” to be the processing of a single record. Records that cause exceptions should be logged, together with a stack trace of the exception.
Web application: For a typical web application in PHP, JSP or ASP.NET, the “unit of work” is the web request. Ideally the application returns a “500 Internal Error”, displays a message to the user (that’s useful but not overly revealing) and logs the stack trace (and possibly other information) so the problem can be investigated. If the application is in debugging mode, it’s sane to display the stack trace to the web browser.
GUI application: The “unit of work” is most often an event handler that’s called by the GUI framework. You push a button, something does wrong, then what? Unlike server-side web applications, which tend to assume that exceptions don’t involve corruption of static memory or of a database, GUI applications tend to shut down when they experience unexpected exceptions. [3] As a result, GUI applications tend to need infrastructure to convert common and predictable exceptions (such as network timeouts) into human readable error messages.
Mail server: A mail server stores messages in a queue and delivers them over a unreliable network. Exceptions occur because of full disks (locally or remote), network failures, DNS misconfigurations, remote server falures, and an occasionaly cosmic ray. The “unit of work” is the delivery of a single message. If an exception is thrown during delivery of the message, it stays in the queue: the mail server attempts to resend on a schedule, discarding it if it is unable to deliver after seven days.
What should you do when you’ve caught one?
That’s the subject of another article. Subscribe to my RSS feed if you want to read it when it’s ready. For now, I’ll enumerate a few questions to think about:
- What do tell the end user?
- What do you tell the developer?
- What do you tell the sysadmin?
- Will the error clear if up if we try to repeat this unit of work again?
- How long would we need to wait?
- Could we do something else instead?
- Did the error happen because the state of the application is corrupted?
- Did the error cause the state of the application to get corrupted?
Conclusion
Error handling is tough. Because errors come from many sources such as software defects, bad user input, configuration mistakes, and both permanent and transient hardware failures, it’s impossible for a developer to anticipate and perfectly handle everything that can go wrong. Exceptions are an excellent method of separating error handling logic from the normal flow of programs, but many programmers are too eager to catch exceptions: this either causes errors to be ignores, or entangles error handling with mainline logic, complicating both. The long term impact is that many programmers are afraid of exceptions and turn to return values as an error signals, which is a step backwards.
A strategy that (i) uses finally as the first resort for containing corrupting and maintaining invariants, (ii) uses catch locally when the exceptions thrown in an area are completely understood, and (iii) surrounds independent units of work with try-catch blocks is an effective basis for using exceptions that can be built upon to develop an exception handling policy for a particular application.
Error handling is a topic that I spend entirely too much time thinking about, so I’ll be writing about it more. Subscribe to my RSS Feed if you think I’ve got something worthwhile to say.

The first language I used that put dictionaries on my fingertips was Perl, where the solution to just about any problem involved writing something like
$hashtable{$key}=$value;
Perl called a dictionary a ‘hash’, a reference to the way Perl implemented dictionaries. (Dictionaries are commonly implemented with hashtables and b-trees, but can also be implemented with linked-list and other structures.) The syntax of Perl is a bit odd, as you’d need to use $, # or % to reference scalar, array or hash variables in different contexts, but dictionaries with similar semantics became widespread in dynamic languages of that and succeeding generations, such as Python, PHP and Ruby. ‘Map’ container classes were introduced in Java about a decade ago, and programmers are using dictionaries increasingly in static languages such as Java and C#.
Dictionaries are a convenient and efficient data structure, but there’s are areas in which different mplementations behave differently: for instance, in what happens if you try to access an undefined key. I think that cross-training is good for developers, so this article compares this aspect of the semantics of dictionaries in four popular languages: PHP, Python, Java and C#.
Use cases
There are two use cases for dictionaries, so far as error handling is concerned:
- When you expect to look up undefined values, and
- When you don’t
Let’s look at three examples:
Computing A Histogram
One common use for a dictionary is for counting items, or recording that items in a list or stream have been seen. In C#, this is typically written something like:
[01] var count=Dictionary<int,int>();
[02] foreach(int i in inputList) {
[03] if (!counts.Contains(i))
[04] count[i]=0;
[05]
[06] count[i]=count[i]+1
[07] }
The Dictionary count now contains the frequency of items inputList, which could be useful for plotting a histogram. A similar pattern can be used if we wish to make a list of unique items found in inputList. In either case, looking up values that aren’t already in the hash is a fundamental part of the algorithm.
Processing Input
Sometimes, we’re getting input from another subsystem, and expect that some values might not be defined. For instance, suppose a web site has a search feature with a number of optional features, and that queries are made by GET requests like:
[08] search.php?q=kestrel [09] search.php?q=admiral&page=5 [10] search.php?q=laurie+anderson&page=3&in_category=music&after_date=1985-02-07
In this case, the only required search parameter is “q”, the query string — the rest are optional. In PHP (like many other environments), you can get at GET variables via a hashtable, specifically, the $_GET superglobal, so (depending on how strict the error handling settings in your runtime are) you might write something like
[11] if ($_GET["q"])) {
[12] throw new InvalidInputException("You must specify a query");
[13] }
[14]
[15] if($_GET["after_date"]) {
[16] ... add another WHERE clause to a SQL query ...
[17] }
This depends, quite precisely, on two bits of sloppiness in PHP and Perl: (a) Dereferencing an undefined key on a hash returns an undefined value, which is something like a null. (b) both languages have a liberal definition of true and false in an if() statement. As a result, the code above is a bit quirky. The if() at line 11 evaluates false if q is undefined, or if q is the empty string. That’s good. However, both the numeric value 0 and the string “0″ also evaluate false. As a result, this code won’t allow a user to search for “0″, and will ignore an (invalid) after_date of 0, rather than entering the block at line [16], which hopefully would validate the date.
Java and C# developers might enjoy a moment of schadenfreude at the above example, but they’ve all seen, written and debugged examples of input handling code that just as quirky as the above PHP code — with several times the line count. To set the record straight, PHP programmers can use the isset() function to precisely test for the existence of a hash key:
[11] if (isset($_GET["q"]))) {
[12] throw new InvalidInputException("You must specify a query");
[13] }
The unusual handling of “0″ is the kind of fault that can survive for years in production software: so long as nobody searches for “0″, it’s quite harmless. (See what you get if you search for a negative integer on Google.) The worst threat that this kind of permissive evaluation poses is when it opens the door to a security attack, but we’ve also seen that highly complex logic that strives to be “correct” in every situation can hide vulnerabilities too.
Relatively Rigid Usage
Let’s consider a third case: passing a bundle of context in an asynchronous communications call in a Silverlight application written in C#. You can do a lot worse than to use the signatures:
[14] void BeginAsyncCall(InputType input,Dictionary<string, object> context,CallbackDelegate callback); [15] void CallbackDelegate(ReturnType returnValue,Dictionary<string,object> context);
The point here is that the callback might need to know something about the context in which the asynchronous function was called to do it’s work. However, this information may be idiosyncratic to the particular context in which the async function is called, and is certainly not the business of the asynchronous function. You might write something like
[16] void Initiator() {
[17] InputType input=...;
[18] var context=Dictionary<string,object>();
[19] context["ContextItemOne"]= (TypeA) ...;
[20] context["ContextItemTwo"]= (TypeB) ...;
[21] context["ContextItemThre"] = (TypeC) ...;
[22] BeginAsyncCall(input,context,TheCallback);
[23] }
[24]
[25] void TheCallback(ReturnType output,Dictionary<string,object> context) {
[26] ContextItemOne = (TypeA) context["ContextItemOne"];
[27] ContextItemTwo = (TypeB) context["ContextItemTwo"];
[28] ContextItemThree = (TypeC) context["ContextItemThree"];
[29] ...
[30] }
This is nice, isn’t it? You can pass any data values you want between Initiator and TheCallback. Sure, the compiler isn’t checking the types of your arguments, but loose coupling is called for in some situations. Unfortunately it’s a little too loose in this case, because we spelled the name of a key incorrectly on line 21.
What happens?
The [] operator on a dot-net Dictionary throws a KeyNotFoundException when we try to look up a key that doesn’t exist. I’ve set a global exception handler for my Silverlight application which, in debugging mode, displays the stack trace. The error gets quickly diagnosed and fixed.
Four ways to deal with a missing value
There are four tools that hashtables give programmers to access values associated with keys and detect missing values:
- Test if key exists
- Throw exception if key doesn’t exist
- Return default value (or null) if key doesn’t exist
- TryGetValue
#1: Test if key exists
PHP: isset($hashtable[$key]) Python: key in hashtable C#: hashtable.Contains(key) Java: hashtable.containsKey(key)
This operator can be used together with the #2 or #3 operator to safely access a hashtable. Line [03]-[04] illustrates a common usage pattern.
One strong advantage of the explicit test is that it’s more clear to developers who spend time working in different language environments — you don’t need to remember or look in the manual to know if the language you’re working in today uses the #2 operator or the #3 operator.
Code that depends on the existence test can be more verbose than alternatives, and can be structurally unstable: future edits can accidentally change the error handling properties of the code. In multithreaded environments, there’s a potential risk that an item can be added or removed between the existance check and an access — however, the default collections in most environment are not thread-safe, so you’re likely to have worse problems if a collection is being accessed concurrently.
#2 Throw exception if key doesn’t exist
Python: hashtable[key] C#: hashtable[key]
This is a good choice when the non-existence of a key is really an exceptional event. In that case, the error condition is immediately propagated via the exception handling mechanism of the language, which, if properly used, is almost certainly better than anything you’ll develop. It’s awkward, and probably inefficient, if you think that non-existent keys will happen frequently. Consider the following rewrite of the code between [01]-[07]
[31] var count=Dictionary<int,int>();
[32] foreach(int i in inputList) {
[33] int oldCount;
[34] try {
[35] oldCount=count[i];
[36] } catch (KeyNotFoundException ex) {
[37] oldCount=0
[38] }
[39]
[40] count[i]=oldCount+1
[41] }
It may be a matter of taste, but I think that’s just awful.
#3 Return a default (often null) value if key doesn’t exist
PHP: $hashtable[key] (well, almost) Python: hashtable.get(key, [default value]) Java: hashtable.get(key)
This can be a convenient and compact operation. Python’s form is particularly attractive because it lets us pick a specific default value. If we use an extension method to add a Python-style GetValue operation in C#, the code from [01]-[07] is simplified to
[42] var count=Dictionary<int,int>(); [43] foreach(int i in inputList) [44] count[i]=count.GetValue(i,0)+1;
It’s reasonable for the default default value to be null (or rather, the default value of the type), as it is in Python, in which case we could use the ??-operator to write
[42] var count=Dictionary<int,int>(); [43] foreach(int i in inputList) [44] count[i]=(count.GetValue(i) ?? 0)+1;
(A ?? B equals A if A is not null, otherwise it equals B.) The price for this simplicity is two kinds of sloppiness:
- We can’t tell the difference between a null (or default) value associated with a key and no value associated with a key
- The potential of null value exports chaos into the environment: trying to use a null value can cause a NullReferenceException if we don’t explictly handle the null. NullReferenceExceptions don’t bother me if they happen locally to the function that returns them, but they can be a bear to understand when a null gets written into an instance variable that’s accessed much later.
Often people don’t care about 1, and the risk of 2 can be handled by specifying a non-null default value.
Note that PHP’s implementation of hashtables has a particularly annoying characteristic. Error handling in php is influenced by the error_reporting configuration variable which can be set in the php.ini file and other places. If the E_STRICT bit is not set in error_reporting, PHP barrels on past places where incorrect variable names are used:
[45] $correctVariableName="some value";
[46] echo "[{$corectValiableName}]"; // s.i.c.
In that case, the script prints “[]” (treats the undefined variable as an empty string) rather than displaying an error or warning message. PHP will give a warning message if E_STRICT is set, but then it applies the same behavior to hashtables: an error message is printed if you try to dereference a key that doesn’t exist — so PHP doesn’t consistently implement type #3 access.
#4 TryGetValue
There are quite a few methods (Try-* methods) in the .net framework that have a signature like this:
[47] bool Dictionary<K,V>.TryGetValue(K key,out V value);
This method has crisp and efficient semantics which could be performed in an atomic thread-safe manner: it returns true if finds the key, and otherwise returns false. The output parameter value is set to the value associated with the key if a value is associated with the key, however, I couldn’t find a clear statement of what happens if the key isn’t found. I did a little experiment:
[48] var d = new Dictionary<int, int>(); [49] d[1] = 5; [50] d[2] = 7; [51] int outValue = 99; [52] d.TryGetValue(55, out outValue) [53] int newValue = outValue;
I set a breakpoint on line 53 and found thate the value of outValue was 0, which is the default value of the int type. It seems, therefore, that TryGetValue returns the default value of the type when it fails to find the key. I wouldn’t count on this behavior, as it is undocumented.
The semantics of TryGetValue are crisp and precise. It’s particularly nice that something like TryGetValue could be implemented as an atomic operation, if the underyling class is threadsafe. I fear, however, that TryGetValue exports chaos into it’s environment. For instance, I don’t like declaring a variable without an assignment, like below:
[54] int outValue;
[55] if (d.TryGetValue(55,outValue)) {
[56] ... use outValue ...
[57] }
The variable outValue exists before the place where it’s set, and outside of the block where it has a valid value. It’s easy for future maintainers of the code to try to use outValue between lines [54]-[55] or after line [57]. It’s also easy to write something like 51], where the value 99 is completely irrelevant to the program. I like the construction
[58] if (d.Contains(key)) {
[59] int value=d[key];
[60] ... do something with value ...
[61] }
because the variable value only exists in the block [56]-[58] where it has a defined value.
Hacking Hashables
A comparison of hashtables in different languages isn’t just academic. If you don’t like the operations that your language gives you for hashtables, you’re free to implement new operations. Let’s take two simple examples. It’s nice to have a Python-style get() in PHP that never gives a warning message, and it’s easy to implement
[62] function array_get($array,$key,$defaultValue=false) {
[63] if (!isset($array[$key]))
[64] return $defaultValue;
[65]
[66] return $array[$key];
[67] }
Note that the third parameter of this function uses a default value of false, so it’s possible to call it in a two-parameter form
[68] $value=array_get($array,$key);
with a default default of false, which is reasonable in PHP.
Extension methods make it easy to add a Python-style get() to C#; I’m going to call it GetValue() to be consistent with TryGetValue():
[69] public static class DictionaryExtensions {
[70] public static V GetValue<K, V>(this IDictionary<K, V> dict, K key) {
[71] return dict.GetValue(key, default(V));
[72] }
[73]
[74] public static V GetValue<K, V>(this IDictionary<K, V> dict, K key, V defaultValue) {
[75] V value;
[76] return dict.TryGetValue(key, out value) ? value : defaultValue;
[77] }
[78] }
Conclusion
Today’s programming languages put powerful data structures, such as dictionaries, on your fingertips. When we look closely, we see subtle differences in the APIs used access dictionaries in different languages. A study of the different APIs and their consequences can help us think about how to write code that is more reliable and maintainable, and informs API design in every language

Many modern languages, such as Java, Perl, PHP and C#, are derived from C. In C, string literals are written in double quotes, and a set of double quotes can’t span a line break. One advantage of this is that the compiler can give clearer error messages when you forget the close a string. Some C-like languages, such as Java and C# are like C in that double quotes can’t span multiple lines. Other languages, such as Perl and PHP, allow it. C# adds a new multiline quote operator, @”" which allows quotes to span multiple lines and removes the special treatment that C-like languages give to the backslash character (\).
The at-quote is particularly useful on the Windows platform because the backslash used as a path separator interacts badly with the behavior of quotes in C, C++ and many other languages. You need to write
String path="C:\\Program Files\\My Program\\Some File.txt";
With at-quote, you can write
String path=@"C:\Program Files\My Program\Some File.txt";
which makes the choice of path separator in MS-DOS seem like less of a bad decision.
Now, one really great thing about SQL is that the database can optimize complicated queries that have many joins and subselects — however, it’s not unusual to see people write something like
command.CommandText = "SELECT firstName,lastName,(SELECT COUNT(*) FROM comments WHERE postedBy =userId AND flag_spam='n') AS commentCount,userName,city,state,gender,birthdate FROM user,user Location,userDemographics WHERE user.userId=userLocation.userId AND user.userId=userDemographi cs.user_id AND (SELECT COUNT(*) FROM friendsReferred WHERE referringUser=userId)>10 ORDER BY c ommentCount HAVING commentCount>3";
(line-wrapped C# example) Complex queries like this can be excellent, because they can run thousands of times faster than loops written in procedural or OO languages which can fire off hundreds of queries, but a query written like the one above is a bit unfair to the person who has to maintain it.
With multiline quotes, you can continue the indentation of your code into your SQL:
command.CommandText = @"
SELECT
firstName
,lastName
,(SELECT COUNT(*) FROM comments
WHERE postedBy=userId AND flag_spam='n') AS commentCount
,userName
,city
,state
,gender
,birthdate
FROM user,userLocation,userDemographics
WHERE
user.userId=userLocation.userId
AND user.userId=userDemographics.user_id
AND (SELECT COUNT(*) FROM friendsReferred
WHERE referringUser=userId)>10
ORDER BY commentCount
HAVING commentCount>3
";
Although this might not be quite quite as cool as LINQ, it works with Mysql, Microsoft Access or any database you need to connect to — and it works in many other languages, such as PHP (in which you could use ordinary double quotes.) In languages like Java that don’t support multiline quotes, you can always write
String query = " SELECT" +" firstName" +" ,lastName" +" ,(SELECT COUNT(*) FROM comments" +" WHERE postedBy=userId AND flag_spam='n') AS commentCount" +" ,userName" +" ,city" +" ,state" +" ,gender" +" ,birthdate" +" FROM user,userLocation,userDemographics" +" WHERE" +" user.userId=userLocation.userId" +" AND user.userId=userDemographics.user_id" +" AND (SELECT COUNT(*) FROM friendsReferred" +" WHERE referringUser=userId)>10" +" ORDER BY commentCount" +" HAVING commentCount>3";
but that’s a bit more cumbersome and error prone.
]]>Statically typed languages such as C# and Java have some advantages: they run faster and IDE’s can understand the code enough to save typing (with your fingers), help you refactor your code, and help you fix errors. Although there’s a lot of things I like symfony, it feels like a Java framework that’s invaded the PHP world. Eclipse would help you deal with the endless getters and setters and domain object methods with 40-character names in Java, Eclipse.
The limits of polymorphism are a serious weakness of today’s statically typed languages. C# and Java apps that I work with are filled with if-then-else or case ladders when they need to initialize a dynamically chosen instance of one of a set of classes that subclass a particular base class or that implement a particular interface. Sure, you can make a HashMap or Dictionary that’s filled with Factory objects, but any answer for that is cumbersome. In PHP, however, you can write
$class_name="Plugin_Module_{$plugin_name}";
$instance = new $class_name($parameters);
This is one of several patterns which make it possible to implement simple but powerful frameworks in PHP.
Mat, on the other hand, uses the ‘magic’ __call() method to implement get and set methods dynamically. This makes it possible to ‘implement’ getters and setters dynamically by simply populating a list of variables, and drastically simplifies the construction and maintainance of domain objects. A commenter suggests that he go a step further and use the __get() and __set() method to implement properties. It’s quite possible to implement active records in PHP with a syntax like
$myTable = $db->myTable; $row = $myTable->fetch($primaryKey); $row->Name="A New Name"; $row->AccessCount = $row->AccessCount+1; $row->save();
I’ve got an experimental active record class that introspects the database (no configuration file!) and implements exactly the above syntax, but it currently doesn’t know anything about joins and relationships. It would be a great day for PHP to have a database abstraction that is (i) mature, (ii) feels like PHP, and (iii) solves (or reduces) the two-artifact problem of maintaining both a database schema AND a set of configuration files that control the active record layer.
The point of this post isn’t that dynamically typed languages are better than statically typed languages, but rather that programmers should make the most of the features of the language they use: no PHP framework has become the ‘rails’ of PHP because no PHP framework has made the most of the dynamic natures of the PHP language.
]]>